markdown-proofing

A markdown proofing platform for individuals, teams, and organizations.
Quickstart: Installation, usage, and build integrations
Install into your project:
> npm install markdown-proofing
Now, create a .markdown-proofing JSON file in the root of your project. Here's a simple one using a preset to get started:
Now, run it (may require global npm installation to run directly at command line):
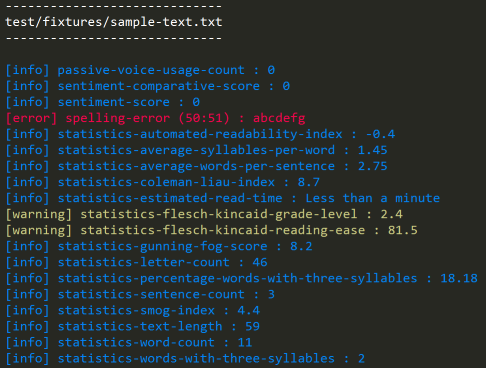
> markdown-proofing ./file1.md
Next, you could wire it up in your package.json as part of your build (or, perhaps as a lint step, you decide!).
Usage with Jekyll / Static Site Generators
This section is centered around Jekyll, but may work with other static site generators, too!
Jekyll itself doesn't use npm. But, markdown-proofing can still be used!
First, check if a package.json file exists in the repository root. If one does, great! If not, no problem -- simply create one using npm init.
After package.json exists, run npm install markdown-proofing --save-dev. This assumes you won't need this package available in your production environment.
Then, add or modify the package.json test script:
"scripts": ,Adjust the above as necessary if the posts live in a different place, or if you use a different file extension.
Now, use npm test to run markdown-proofing on the posts!
Configuration
Configuration is specified in JSON.
By default .markdown-proofing located in the root of the project is used. You can optionally specify a different file using the -c / --configuration flags, if you'd like.
The configuration can be as simple as:
Or, a bit more complex:
Spellcheck
The SpellingAnalyzer implements markdown-spellcheck. This package uses a .spelling file for permitting unrecognized text. Only global words are currently supported, though (no file specific words).
markdown-spellcheck also includes an interactive CLI, which you can use to interactively fix spelling and update the .spelling file as necessary. You may find this useful.
Core concepts
There are two core concepts: Analyzers and Rules.
- Analyzers process the text!
- Analyzers parse a markdown text string and return an
AnalyzerResult, which includes a collection ofAnalyzerMessageobjects.AnalyzerMessage's are{ type: String, text: String, line: Number, column: Number }.
- There are useful analyzers built-in and ready for use. Custom analyzers are supported as well.
- Analyzers parse a markdown text string and return an
- Rules react to analyzers!
- These react to the output of the configured analyzers. Without any rules, the output of the analyzers is not surfaced to the user or applied in any way. So, you'll need some rules!
- Rules are in the format of
'{{message-type}}': '{{condition}}'.- Example rule:
'statistics-word-count': 'info' - Example rule:
'statistics-flesch-kincaid-reading-ease': 'warning < 40'
- Example rule:
- There are four types of rules:
info,warning,error, andnone.infosignals to add this to any output. It should show up in build results and any place where messages should be visible.warningis a standard warning, it shouldn't fail a build.errorviolations should result in a build failure.noneis used to override a preset.
- Rules can have an optional condition, which is applied as
warning < 40-- it's awarningonly when the value is less than40.- This is useful for statistics and other numerical outputs from analyzers.
Jekyll Integration
You can use the following to integrate with Jekyll:
package.json
"scripts": ,"devDependencies": proofScripts.js
; const arg = processargv2;if !arg ; ; const filePattern = processargv3;if !filePattern ; ; if arg === 'latest' const orderedPosts = ; if orderedPostslength > 0 const latestPost = orderedPosts0; ; else if arg === 'git-index' ;else if arg === 'git-uncommitted' ;else if arg === 'git-index-and-uncommitted' ; { if ! ; ; if !Array gitDiffPatterns = gitDiffPatterns ; const files = ; gitDiffPatterns; if fileslength === 0 ; ; ;} { if !Array files = files ; const cmd = `npm run proof `; if code !== 0 ; ; }Custom Analyzers
; // TODO: Change this import if this is not correct { const result = ; // As part of the logic, optionally add one or more messages: result; // The return value can be an `AnalyzerResult` // or a promise to return an `AnalyzerResult`. return result; }Then, simply wire it up in configuration as an analyzers array item:
Author
Ritter Insurance Marketing
License
MIT
Contributing
Contributions are highly welcome! However, before making large changes that may be outside the scope of this project, we may want to discuss it in an issue prior to opening a pull request.
If you construct an analyzer useful to you and/or your team/company and it could be useful for others, we'd appreciate a pull request to incorporate it into the project!