ScrapeMeta
A library to easily scrape metadata from an article on the web using Open Graph metadata, regular HTML metadata, and series of fallbacks. Following a few principles:
- Have a high accuracy for online articles by default.
- Be usable on the server and in the browser.
- Make it simple to add new rules or override existing ones.
- Don't restrict rules to CSS selectors or text accessors.
Table of Contents
- Example
- Metadata
- Comparison
- Installation
- Server-side Usage
- Browser-side Usage
- Creating & Overriding Rules
- API
- License
Example
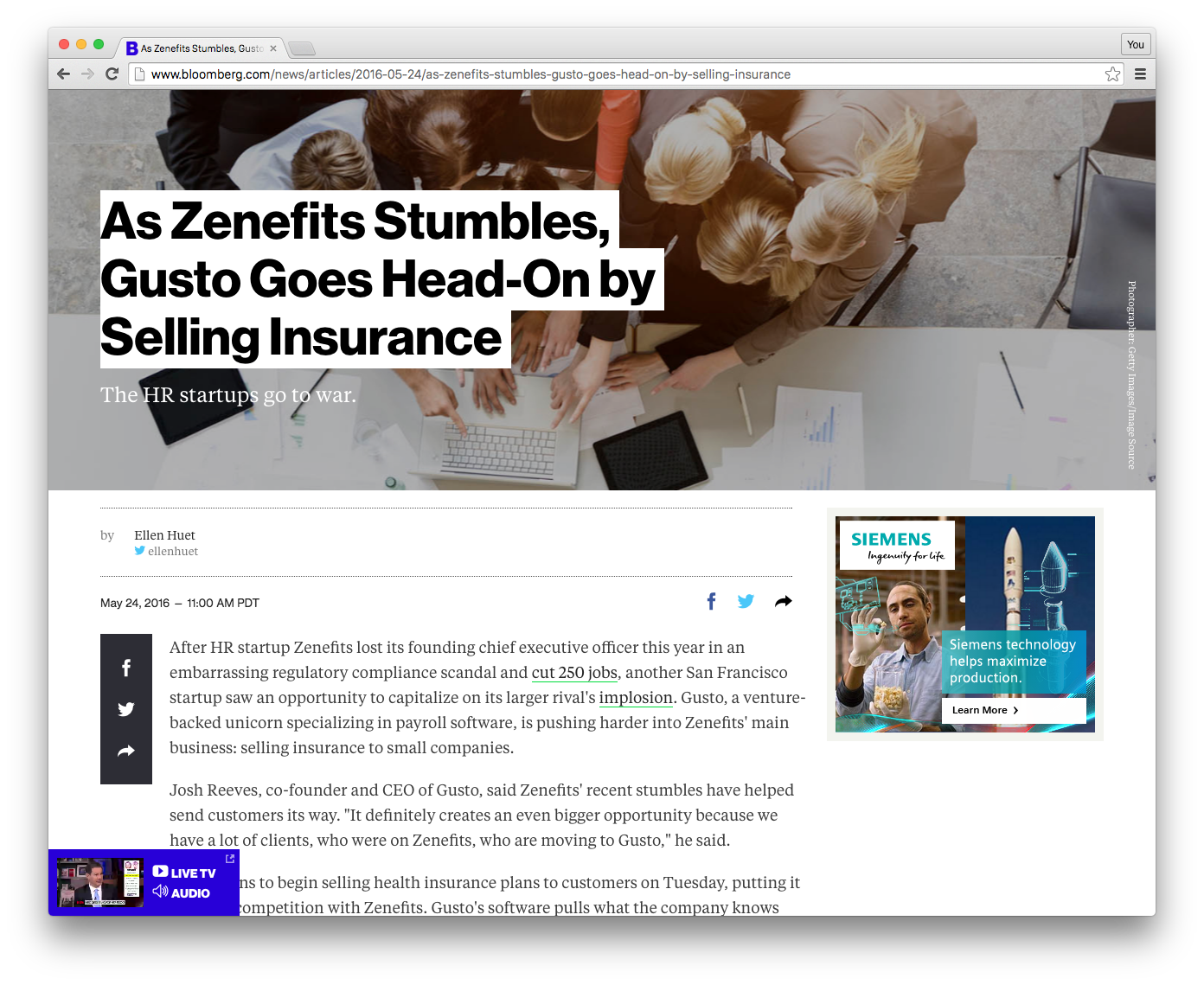
Using ScrapeMeta, this metadata...
{
"favicon": "https://assets.bwbx.io/business/public/images/favicons/favicon-16x16-cc2a6c3317.png"
"author": "Ellen Huet",
"date": "2016-05-24T18:00:03.894Z",
"description": "The HR startups go to war.",
"image": "https://assets.bwbx.io/images/users/iqjWHBFdfxIU/ioh_yWEn8gHo/v1/-1x-1.jpg",
"publisher": "Bloomberg.com",
"title": "As Zenefits Stumbles, Gusto Goes Head-On by Selling Insurance",
"url": "http://www.bloomberg.com/news/articles/2016-05-24/as-zenefits-stumbles-gusto-goes-head-on-by-selling-insurance"
}
...would be scraped from this article...
Metadata
Here is a list of the metadata that Metascraper collects by default:
-
favicon— eg.https://example.com/icon.ico
The favicon of the web. It will default to the highest resolution possible. -
author— eg.Noah Kulwin
A human-readable representation of the author's name. -
date— eg.2016-05-27T00:00:00.000Z
An ISO 8601 representation of the date the article was published. -
description— eg.Venture capitalists are raising money at the fastest rate...
The publisher's chosen description of the article. -
image— eg.https://assets.entrepreneur.com/content/3x2/1300/20160504155601-GettyImages-174457162.jpeg
An image URL that best represents the article. -
publisher— eg.Fast Company
A human-readable representation of the publisher's name. -
title— eg.Meet Wall Street's New A.I. Sheriffs
The publisher's chosen title of the article. -
url— eg.http://motherboard.vice.com/read/google-wins-trial-against-oracle-saves-9-billion
The URL of the article.
Comparison
To give you an idea of how accurate Metascraper is, here is a comparison of similar libraries:
| Library | metascraper |
html-metadata |
node-metainspector |
open-graph-scraper |
unfluff |
|---|---|---|---|---|---|
| Correct | 95.54% | 74.56% | 61.16% | 66.52% | 70.90% |
| Incorrect | 1.79% | 1.79% | 0.89% | 6.70% | 10.27% |
| Missed | 2.68% | 23.67% | 37.95% | 26.34% | 8.95% |
A big part of the reason for Metascraper's higher accuracy is that it relies on a series of fallbacks for each piece of metadata, instead of just looking for the most commonly-used, spec-compliant pieces of metadata, like Open Graph. Metascraper's default settings are targetted specifically at parsing online articles, which is why it's able to be more highly-tuned than the other libraries for that purpose.
If you're interested in the breakdown by individual pieces of metadata, check out the full comparison summary, or dive into the raw result data for each library.
Installation
Simply install with npm:
npm install metascraper
Server-side Usage
On the server, you're typically going to only have a url to scrape, or already have the html downloaded. Here's what a simple use case might look like:
Metascraper // {// "author": "Ellen Huet",// "date": "2016-05-24T18:00:03.894Z",// "description": "The HR startups go to war.",// "image": "https://assets.bwbx.io/images/users/iqjWHBFdfxIU/ioh_yWEn8gHo/v1/-1x-1.jpg",// "publisher": "Bloomberg.com",// "title": "As Zenefits Stumbles, Gusto Goes Head-On by Selling Insurance"// }Or, if you are using async/await, you can simply do:
const metadata = await MetascraperSimilarly, if you already have the html downloaded, you can use the scrapeHtml method instead:
const metadata = await MetascraperThat's it! If you want to customize what exactly gets scraped, check out the documention on the rules system.
Browser-side Usage
In the browser, for example inside of a Chrome extension, you might already have access to the window of the document you'd like to scrape. You can simply use the scrapeWindow method to get the metadata:
Metascraper // {// "author": "Ellen Huet",// "date": "2016-05-24T18:00:03.894Z",// "description": "The HR startups go to war.",// "image": "https://assets.bwbx.io/images/users/iqjWHBFdfxIU/ioh_yWEn8gHo/v1/-1x-1.jpg",// "publisher": "Bloomberg.com",// "title": "As Zenefits Stumbles, Gusto Goes Head-On by Selling Insurance"// }Or if you are using async/await it might look even simpler:
const metadata = await MetascraperOf course, you can also still scrape directly from html or a url if you choose to.
Creating & Overiding Rules
By default, Metascraper ships with a set of rules that are tuned to parse out information from online articles—blogs, newspapers, press releases, etc. But you don't have to use the default rules. If you have a different use case, supplying your own rules is easy to do.
Each rule is simply a function that receives a Cheerio instance of the document, and that returns the value it has scraped. (Or a Promise in the case of asynchronous scraping.) Like so:
{ const text = text return text}All of the rules are then packaged up into a single dictionary, which has the same shape as the metadata that will be scraped. Like so:
const MY_RULES = title: myTitleRule summary: mySummaryRule ...And then you can pass that rules dictionary into any of the scraping functions as the second argument, like so:
const metadata = MetascraperNot only that, but instead of being just a function, rules can be passed as an array of fallbacks, in case the earlier functions in the array don't return results. Like so:
const MY_RULES = title: myPreferredTitleRule myFallbackTitleRule mySuperLastResortTitleRule The beauty of the system is that it means simple scraping needs can be defined inline easily, like so:
const rules = text text const metadata = MetascraperBut in more complex cases, the set of rules can be packaged separately, and even shared with others, for example:
const metadata = MetascraperAnd if you want to use the default rules, but with a few tweaks of your own, it's as simple as extending the object:
const NEW_RULES = ...MetascraperRULES summary: mySummaryRule title: myPreferredTitleRule myFallbackTitleRule mySuperLastResortTitleRule const metadata = MetascraperFor a more complex example of how rules work, check out the default rules.
API
Metascraper.scrapeUrl(url, [rules])
Metascraper const metadata = await MetascraperScrapes a url with an optional set of rules.
Metascraper.scrapeHtml(html, [rules])
Metascraper const metadata = await MetascraperScrapes an html string with an optional set of rules.
Metascraper.scrapeWindow(window, [rules])
Metascraper const metadata = await MetascraperScrapes a window object with an optional set of rules.
Metascraper.RULES
A dictionary of the default rules, in case you want to extend them.