

Validate XML, Parse XML to JS Object, or Build XML from JS Object without C/C++ based libraries and no callback.
![]()
- Validate XML data syntactically. Use detailed-xml-validator to verify business rules.
- Parse XML to JS Objectand vice versa
- Common JS, ESM, and browser compatible
- Faster than any other pure JS implementation.
It can handle big files (tested up to 100mb). XML Entities, HTML entities, and DOCTYPE entites are supported. Unpaired tags (Eg <br> in HTML), stop nodes (Eg <script> in HTML) are supported. It can also preserve Order of tags in JS object
We've recently launched Flowgger

Don't forget to check our new library Text2Chart that constructs flow chart out of simple text. Very helpful in creating or alayzing an algorithm, and documentation purpose.
Sponsor this project



This is a donation. No goods or services are expected in return. Any requests for refunds for those purposes will be rejected.


















The list of users are mostly published by Github or communicated directly. Feel free to contact if you find any information wrong.
To use as package dependency
$ npm install fast-xml-parser
or
$ yarn add fast-xml-parser
To use as system command
$ npm install fast-xml-parser -g
To use it on a webpage include it from a CDN
Example
As CLI command
$ fxparser some.xmlIn a node js project
const { XMLParser, XMLBuilder, XMLValidator} = require("fast-xml-parser");
const parser = new XMLParser();
let jObj = parser.parse(XMLdata);
const builder = new XMLBuilder();
const xmlContent = builder.build(jObj);In a HTML page
<script src="path/to/fxp.min.js"></script>
:
<script>
const parser = new fxparser.XMLParser();
parser.parse(xmlContent);
</script>Bundle size
| Bundle Name | Size |
|---|---|
| fxbuilder.min.js | 6.5K |
| fxparser.min.js | 20K |
| fxp.min.js | 26K |
| fxvalidator.min.js | 5.7K |
| v3 | v4 and v5 | v6 |
| documents |
note:
- Version 6 is released with version 4 for experimental use. Based on it's demand, it'll be developed and the features can be different in final release.
- Version 5 has the same functionalities as version 4.
negative means error


- Y-axis: requests per second
- X-axis: File size

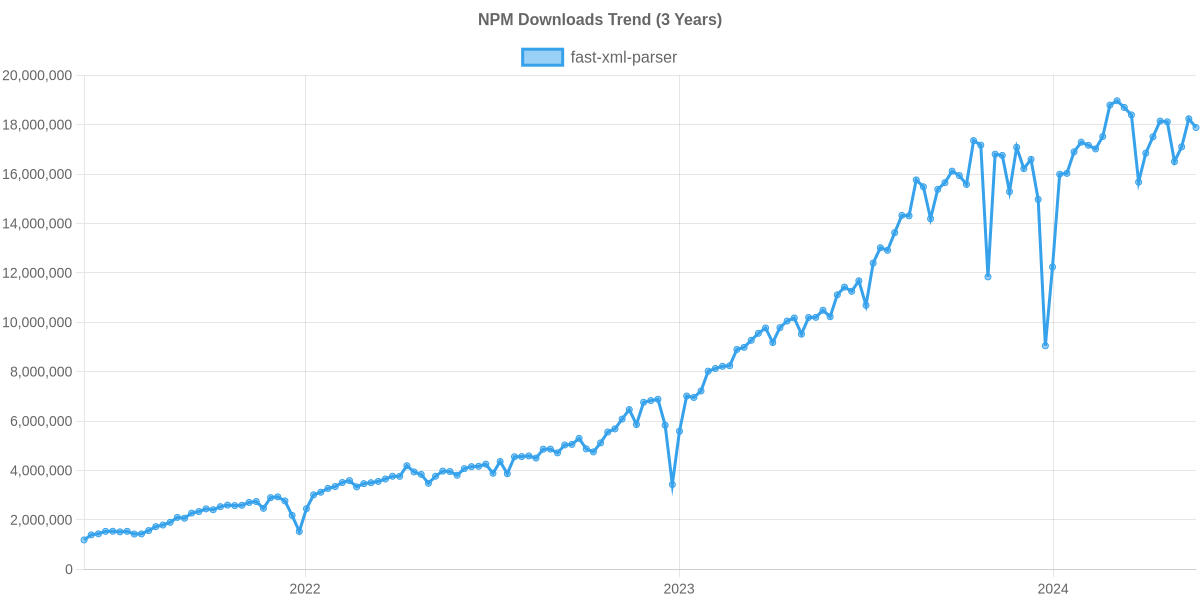
Usage Trend of fast-xml-parser
This project exists thanks to all the people who contribute. [Contribute].

Thank you to all our backers! 🙏 [Become a backer]

- MIT License
