



![]()
Elasticsearch cli Data Importer
see faq
Features
- Can Index(import) very large files.
- Runs on any platform (Windows, Mac, Linux)
- Easy to use
- Ability to provide a command-line encoded config. No need to create a local config file
Install
Install Nodejs if you haven't already.
Node.js version 11.10 or higher is required.
Then install the package globally:
npm i -g duckimport
or
yarn global add duckimport
Demo
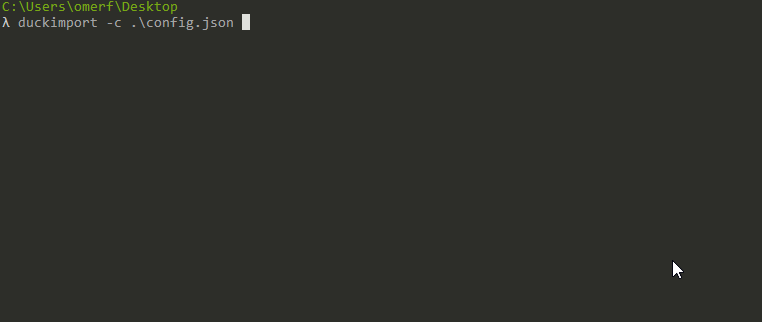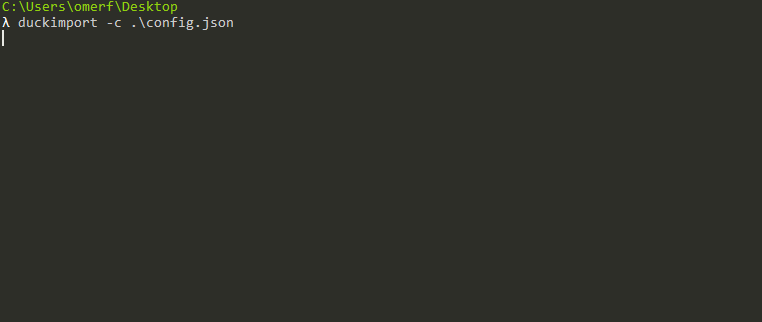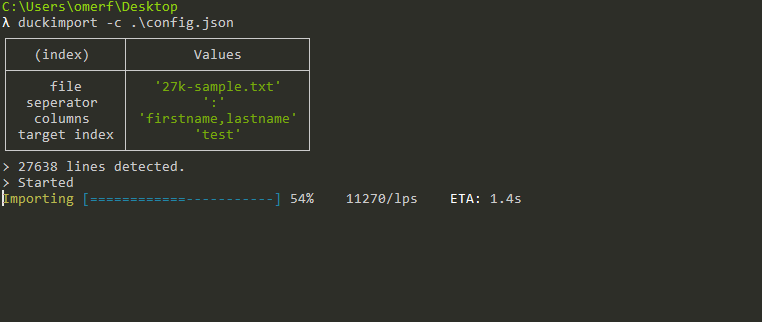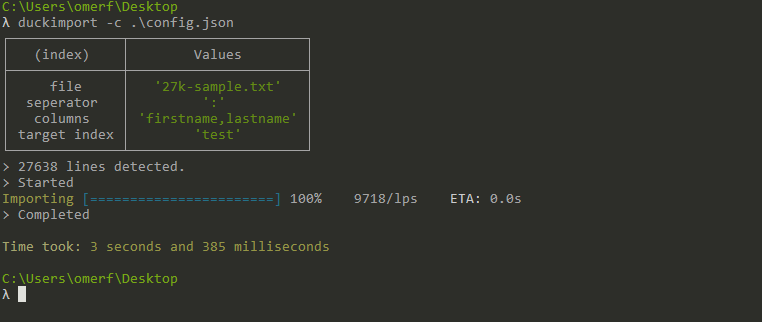
Usage
duckimport <command>
You can see available options with duckimport --help
Usage: duckimport [options]
Options:
-c, --config <path> config file path
-i, --inline <configString> base64 encoded config object
-h, --help output usage information
Examples:
$ duckimport -c ./config.json
$ duckimport -i NDJjNGVx........GZzZGY=
Examples
duckimport -c ./config.jsonduckimport -i ewogICAgIm.....KfQ==
You will need a proper json config in order to run duckimport
An example config file:
{
"client": {
"node": "http://localhost:9200"
},
"file": "bigFile.csv",
"separator": ",",
"columns": [
"firstname",
"lastname"
],
"lines": 10000,
"createNewIndex": true,
"index": {
"index": "peopleIndex",
"body": {
"settings": {
"number_of_replicas": 0,
"auto_expand_replicas": false
},
"mappings": {
"properties": {
"firstname": {
"type": "keyword"
},
"lastname": {
"type": "keyword"
}
}
}
}
}
}config
You can pass a config file using duckimport -c <config file path>
or
duckimport -i <base64 encoded config object>
-
client- Type: Object
- Elasticsearch client configuration. Reference
-
file- Type: String
- The file you want to import(aka. indexing) into Elasticsearch. Can be .txt .csv .tsv etc.
-
separator- Type: String
- The separator between your data's columns
- Exp: ";", ":", "," etc.
-
columns- Type: Array
- Array of column headers or field names. If there is a non-specified headers they won't be imported.
-
lines- Type: Number
- Number of lines included in every chunk sent to the Elasticsearch
-
createNewIndex- Type: Boolean
-
index- Type: Object
- Index configuration. Reference
- index field is represents your Index name and it's mandatory. You don't need to include a body field or so if you set createNewIndex: false
F.A.Q
How does it work?
duckimport process your files in any size line by line and send them into Elasticsearch as chunks. Thanks to nexline
What is lps mean?
Lines Per Seconds. Represents how many lines of your file is processing in a second,
How can I use without a config file?
You can use inline base64 encoded config string using -i flag. All you need is prepare your config object(json or js object and encode it using base64. duckimport will decode the encoded string and process it.
Milestones
- [ ] duckimport GUI - 100+ Github stars
Duck icon made by Freepik from http://www.flaticon.com/