


This is an ultra-fast NodeJS, Bun, and Deno interface to LMDB; probably the fastest and most efficient key-value/database interface that exists for storage and retrieval of structured JS data (objects, arrays, etc.) in a true persisted, scalable, ACID compliant database. It provides a simple interface for interacting with LMDB, as a key-value db, that makes it easy to fully leverage the power, crash-proof design, and efficiency of LMDB using intuitive JavaScript, and is designed to scale across multiple processes or threads. Several key features that make it idiomatic, highly performant, and easy to use LMDB efficiently:
- High-performance translation of JS values and data structures to/from binary key/value data
- Queueing asynchronous off-thread write operations with promise-based API
- Simple transaction management
- Iterable queries/cursors
- Record versioning and optimistic locking for scalability/concurrency
- Optional native off-main-thread compression with high-performance LZ4 compression
- And ridiculously fast and efficient, with integrated (de)serialization, data retrieval can be several times faster than
JSONalone
lmdb-js is used in many heavy-use production applications, including as a high-performance cache for builds in Parcel and Elasticsearch's Kibana, as the storage layer for HarperDB and Gatsby's database, and for search and analytical engine for clinical medical research.



This library is published to the NPM package lmdb (the 1.x versions were published to lmdb-store), and can be installed with:
npm install lmdb
lmdb-js is based on the Node-API for maximum compatibility across all supported Node versions and future Deno versions. It also includes accelerated, high-speed functions for direct V8 interaction that are compiled for, and (automatically) loaded in Node v16. The standard Node-API based functions are used in all other versions and still provide excellent performance, but for absolute maximum performance on older versions of Node, you can use npm install --build-from-source.
In Deno, this package should be loaded using the NPM module identifier (which will download the package):
import { open } from 'npm:lmdb';Note that Deno and Bun's support for NAPI is not very stable yet, and currently asynchronous transactions (transaction method) are not supported (Bun issue here).
This library has minimal, tightly-controlled, and maintained dependencies to ensure stability, security, and efficiency. It supports both native ESM and CJS usage.
This library handles translation of JavaScript values, primitives, arrays, and objects, to and from the binary storage of LMDB keys and values with highly optimized native C++ code for breakneck performance. It supports multiple types of JS values for keys and values, making it easy to use idiomatic JS for storing and retrieving data in LMDB.
lmdb-js is designed for synchronous reads, and asynchronous writes. In idiomatic JavaScript code, I/O operations are performed asynchronously. LMDB is a memory-mapped database, reading and writing within a transaction does not use any I/O (other than the slight possibility of a page fault), and can usually be performed faster than the event queue callbacks can even execute, and it is easier to write code for instant synchronous values from reads. On the otherhand, commiting transactions does involve I/O, and vastly higher throughput can be achieved by batching operations and executing on a separate thread. Consequently, lmdb-js is designed for transactions to go through this asynchronous batching process and return a simple promise that resolves once data is written and flushed to disk.
With the default syncing configuration, LMDB has a crash-proof design; a machine can be turned off at any point, and data can not be corrupted unless the written data is actually changed or tampered. Writing data and waiting for confirmation that it has been written to the physical medium is critical for data integrity, but is well known to have latency (although not necessarily less efficient). However, by batching writes, when a database is under load, slower transactions enable more writes per transaction, and this library is able to drive LMDB to achieve the maximum levels of throughput with fully synced operations, preserving both the durability/safety of the transactions and unparalleled performance.
This library supports and encourages the use of conditional writes; this allows for atomic operations that are dependent on previously read data, and most transactional types of operations can be written with an optimistic-locking based, atomic-conditional-write pattern. This allows this library to delegate writes to off-thread execution, and scale to handle concurrent execution across many processes or threads while maintaining data integrity.
This library automatically handles database growth, expanding file size with a smart heuristic that minimizes file fragmentation (as you would expect from a database).
This library provides optional compression using LZ4 that works in conjunction with the asynchronous writes by performing the compression in the same thread (off the main thread) that performs the writes in a transaction. LZ4 is extremely fast, and decompression can be performed at roughly 5GB/s, so excellent storage efficiency can be achieved with almost negligible performance impact.
An LMDB database instance is created by using open export from the main module:
import { open } from 'lmdb'; // or require
let myDB = open({
path: 'my-db',
// any options go here, we can turn on compression like this:
compression: true,
});
await myDB.put('greeting', { someText: 'Hello, World!' });
myDB.get('greeting').someText // 'Hello, World!'
// or
myDB.transaction(() => {
myDB.put('greeting', { someText: 'Hello, World!' });
myDB.get('greeting').someText // 'Hello, World!'
});(see database options below for more options)
Once you have opened a database, you can store and retrieve values using keys:
You can store a wide variety of JavaScript values and data structures in this library, including objects (with arbitrary complexity), arrays, buffers, strings, numbers, etc. in your database. Even full structural cloning (with cycles) is optionally supported. Values are stored and retrieved according to the database encoding, which can be set using the encoding property on the database options. By default, data is stored using MessagePack, but there are several supported encodings:
-
msgpack(default) - All values are stored by serializing the value as MessagePack (using the msgpackr package). Values are decoded and parsed on retrieval, sogetandgetRangewill return the object, array, or other value that you have stored. The msgpackr package is extremely fast (usually faster than native JSON), and provides the most flexibility in storing different value types. See the Shared Structures section for how to achieve maximum efficiency with this. -
cbor- This specifies all values use the CBOR format, which requires that the cbor-x package be installed. This package is based on msgpackr and supports all the same options. -
json- All values are stored by serializing the value as JSON (using JSON.stringify) and encoded with UTF-8. Values are decoded and parsed on retrieval using JSON.parse. Generally this does not perform as all as msgpack, nor support as many value types. -
string- All values should be strings and stored by encoding with UTF-8. Values are returned as strings fromget. -
binary- Values are returned as binary arrays (Bufferobjects in NodeJS), representing the raw binary data. Note that creating buffer objects has some overhead and while this is fast and valuable direct storage of binary data, the data encodings provides faster and more optimized process for serializing and deserializing structured data. -
ordered-binary- Use the same encoding as the default encoding for keys, which serializes any JS primitive value with consistent ordering. This is primarily useful indupSortdatabases where data values are ordered, and having consistent key and value ordering is helpful. Note, that this has a same size limit of 8KB (since it is intended for keys which also have similar size limits).
In addition, you can use asBinary to directly store a buffer or Uint8Array as a value, bypassing any encoding.
When using the various APIs, keys can be any JS primitive (string, number, boolean, symbol), an array of primitives, or a Buffer. Using the default ordered-binary conversion, primitives are translated to binary keys used by LMDB in such a way that consistent ordering is preserved. Numbers are ordered naturally, which come before strings, which are ordered lexically. The keys are stored with type information preserved. The getRangeoperations that return a set of entries will return entries with the original JS primitive values for the keys. If arrays are used as keys, they are ordered by first value in the array, with each subsequent element being a tie-breaker. Numbers are stored as doubles, with reversal of sign bit for proper ordering plus type information, so any JS number can be used as a key. For example, here is the order of some different keys:
null // lowest possible value
Symbol.for('even symbols')
false
true
-10 // negative supported
-1.1 // decimals supported
400
3E10
'Hello'
['Hello', 'World']
'World'
'hello'
['hello', 1, 'world']
['hello', 'world']
Buffer.from([255]) // buffers are used directly, 255 is higher than any byte produced by primitivesKeys use 0/null bytes as delimiters for arrays, and so strings currently can not have '\x00' (null char) in them. Buffers are assumed to be already encoded values, and will not be returned as buffers when read (from range queries).
By default, the maximum key size is 1978 bytes. If you explicitly set the pageSize to 8192 or higher, the maximum key size will be 4026, but this is the largest key size supported.
You can override the default encoding of keys, and cause keys to be returned as binary arrays (Buffers in NodeJS) using the keyEncoding: 'binary' database option (generally slower). Use keyEncoding: 'uint32' for keys that are strictly 32-bit unsigned integers, or provide a custom key encoder/decoder with keyEncoder (see custom key encoding).
Once you created have a db, the following methods are available:
This will retrieve the value at the specified key. The key must be a JS value/primitive as described above, and the return value will be the stored data (dependent on the encoding), or undefined if the entry does not exist. The options argument may be used to specify an explicit read transaction.
This will retrieve the entry at the specified key. The key must be a JS value/primitive as described above, and the return value will be the stored entry, or undefined if the entry does not exist. An entry is object with a value property for the value in the database (as returned by db.get), and a version property for the version number of the entry in the database (if useVersions is enabled for the database). The options argument may be used to specify an explicit read transaction.
This will store the provided value/data at the specified key. If the database is using versioning (see options below), the version parameter will be used to set the version number of the entry. If the ifVersion parameter is set, the put will only occur if the existing entry at the provided key has the version specified by ifVersion at the instance the commit occurs (LMDB commits are atomic by default). If the ifVersion parameter is not set, the put will occur regardless of the previous value.
This operation will be enqueued to be written in a batch transaction. Any other operations that occur within the current event turn (until next event after I/O by default) will also occur in the same transaction. This will return a promise for the completion of the put. The promise will resolve once the transaction has finished committing. The resolved value of the promise will be true if the put was successful, and false if the put did not occur due to the ifVersion not matching at the time of the commit. Once the promise resolves, the transaction will have been fully written to the physical storage medium (durable commit, guaranteed available in the future as far as the OS/physical storage can permit and confirm, even if there is power loss or system crash).
If put is called inside a transaction, the put will be executed immediately in the current transaction.
This will delete the entry at the specified key. This functions is similar to put, with the same optional conditional version. This is batched along with put operations, and returns a promise indicating the success of the operation.
Again, if this is performed inside a transation, the removal will be performed in the current transaction.
If you are using a database with duplicate entries per key (with dupSort flag), you can specify the value to remove as the second parameter (instead of a version).
This will run the provided callback in a transaction, asynchronously starting the transaction, then running the callback, then later committing the transaction. By running within a transaction, the code in the callback can perform multiple database operations atomically and isolated (fully ACID compliant). Any put or remove operations are immediately written to the transaction and can be immediately read afterwards (you can call get() or getRange() without awaiting for a returned promise) in the transaction.
The callback function will be queued along with other put and remove operations, and run in the same transaction as other operations that have been queued in the current event turn, and will be executed in the order they were called. transaction will return a promise that will resolve once its transaction has been committed. The promise will resolve to the value returned by the callback function.
For example:
let products = open(...);
// decrement count if above zero
function buyShoe() {
return products.transaction(() => {
let shoe = products.get('shoe')
// this is performed atomically, so we can guarantee no other processes
// modify this entry before we write the new value
if (shoe.count > 0) {
shoe.count--
products.put('shoe', shoe)
return true // succeeded
}
return false // count is zero, no shoes to buy
})
}Note that db.transaction(() => db.put(...)) is functionally the same as calling db.put(...), queuing the put for asynchronously being committed in transaction, except that put executes the database's write operation entirely in separate worker thread, whereas transaction must also synchronize the callback function in the main JS thread to execute (so it is a little bit less efficient, although still quite fast).
Also, the callback function can be an async function (or return a promise), but this is not recommended. If the function returns a promise, this will delay/defer the commit until the callback's promise is resolved. However, while waiting for the callback to finish, other code may execute operations that would end up in the current transaction and may result in a surprising order of operations, and long running transactions are generally discouraged since they extend the single write lock.
This will run the provided callback in a transaction much like transaction except an explicit child transaction will be used specifically for this callback. This makes it possible for the operations to be aborted and rolled back. The callback may return the exported ABORT constant to abort the child transaction for this callback. Also, if the callback function throws an error (or returns a reject promise), this will also abort the child transaction. This childTransaction function is not available if caching or useWritemap is enabled.
The childTransaction function can be executed on its own (to run the child transaction inside the next queued transaction), or it can be executed inside another transaction callback, executing the child transaction within the current transaction.
Returns the transaction id of the currently executing transaction. This is an integer that increments with each
transaction. This is only available inside transaction callbacks (for transactionSync or asynchronous transaction),
and does not provide access transaction ids for asynchronous put/delete methods (the aftercommit method can be
used for that).
This is a promise-like object that resolves when all previous writes have been committed.
This is a promise-like object that resolves when all previous writes have been committed and fully flushed/synced to disk/storage.
This will set the provided value at the specified key, but will do so synchronously. If this is called inside of a transaction, the put will be performed in the current transaction. If not, a transaction will be started, the put will be executed, the transaction will be committed, and then the function will return. We do not recommend this be used for any high-frequency operations as it can be vastly slower (often blocking the main JS thread for multiple milliseconds) than the put operation (typically consumes a few microseconds on a worker thread). The third argument may be a version number or an options object that supports append, appendDup, noOverwrite, noDupData, and version for corresponding LMDB put flags.
This will delete the entry at the specified key. This functions like putSync, providing synchronous entry deletion, and uses the same arguments as remove. This returns true if there was an existing entry deleted, false if there was no matching entry.
This executes a block of conditional writes, and conditionally execute any puts or removes that are called in the callback, using the provided condition that requires the provided key's entry to have the provided version.
This executes a block of conditional writes, and conditionally execute any puts or removes that are called in the callback, using the provided condition that requires the provided key's entry does not exist yet.
This will begin a synchronous transaction, executing the provided callback function, and then commit the transaction. The provided function can perform gets, puts, and removes within the transaction, and the result will be committed. The callback function can return a promise to indicate an ongoing asynchronous transaction, but generally you want to minimize how long a transaction is open on the main thread, at least if you are potentially operating with multiple processes.
The callback may return the exported ABORT constant, or throw an error from the callback, to abort the transaction for this callback.
If this is called inside an existing transaction and child transactions are supported (no write maps or caching), this will execute as a child transaction (and can be aborted), otherwise it will simply execute as part of the existing transaction (in which case it can't be aborted).
This starts a cursor-based query of a range of data in the database, returning an iterable that also has map, filter, and forEach methods. The start and end indicate the starting and ending key for the range. The reverse flag can be used to indicate reverse traversal. The limit can limit the number of entries returned. The returned cursor/query is lazy, and retrieves data as iteration takes place, so a large range could specified without forcing all the entries to be read and loaded in memory upfront, and one can exit out of the loop without traversing the whole range in the database. The query is iterable, we can use it directly in a for-of:
for (let { key, value } of db.getRange({ start, end })) {
// for each key-value pair in the given range
}Or we can use the provided iterative methods on the returned results:
db.getRange({ start, end })
.filter(({ key, value }) => test(key))
.forEach(({ key, value }) => {
// for each key-value pair in the given range that matched the filter
})Note that map and filter are also lazy, they will only be executed once their returned iterable is iterated or forEach is called on it. The map and filter functions also support async/promise-based functions, and you can create an async iterable if the callback functions execute asynchronously (return a promise).
We can also query with offset to skip a certain number of entries, and limit the number of entries to iterate through:
db.getRange({ start, end, offset: 10, limit: 10 }) // skip first 10 and get next 10If you want to get a true array from the range results, the asArray property will return the results as an array.
With an array, map and filter callbacks are immediately executed, but with range iterators, they are executed during iteration, so if an error occurs during iteration, the error will be thrown when the iteration is attempted. It is also critical that when an iteration is finished, the cursor is closed, so by default, if an error occurs during iteration, the cursor will immediately be closed. However, if you want to catch errors that occur in map (and flatMap) callbacks during iteration, you can use the mapError method to catch errors that occur during iteration, and allow iteration to continue (without closing the cursor). For example:
let mapped = db.getRange({ start, end }).map(({ key, value }) => {
return thisMightThrowError(value);
}).mapError((error) => {
// rather than letting the error terminate the iteration, we can catch it here and return a value to continue iterating:
return 'error occurred';
})
for (let entry of mapped) {
...
}A mapError callback can return a value to continue iterating, or throw an error to terminate the iteration.
By default, a range iterator will use a database snapshot, using a single read transaction that remains open and gives a consistent view of the database at the time it was started, for the duration of iterating through the range. However, if the iteration will take place over a long period of time, keeping a read transaction open for a long time can interfere with LMDB's free space collection and reuse and increase the database size. If you will be using a long duration iterator, you can specify snapshot: false flag in the range options to indicate that it snapshotting is not necessary, and it can reset and renew read transactions while iterating, to allow LMDB to collect any space that was freed during iteration.
When using a database with duplicate entries per key (with dupSort flag), you can use this to retrieve all the values for a given key. This will return an iterator just like getRange, except each entry will be the value from the database:
let db = db.openDB('my-index', {
dupSort: true,
encoding: 'ordered-binary',
});
await db.put('key1', 'value1');
await db.put('key1', 'value2');
for (let value of db.getValues('key1')) {
// iterate values 'value1', 'value2'
}
await db.remove('key', 'value1'); // only remove the second value under key1
for (let value of db.getValues('key1')) {
// just iterate value 'value1'
}You can optionally provide a second argument with the same options that getRange handles. You can provide a start and/or end values, which will define the starting value and ending value for the range of values to return for the key:
for (let value of db.getValues('key1', { start: 'value1', end: 'value3'})) ...Using start/end is only supported if using the ordered-binary encoding.
This behaves like getRange, but only returns the keys. If this is a duplicate key database, each key is only returned once (even if it has multiple values/entries).
Here are the options that can be provided to the range methods (all are optional):
-
start: Starting key (will start at beginning of db, if not provided), can be any valid key type (primitive or array of primitives). -
end: Ending key (will finish at end of db, if not provided), can be any valid key type (primitive or array of primitives). -
reverse: Boolean key indicating reverse traversal through keys (does not do reverse by default). -
limit: Number indicating maximum number of entries to read (no limit by default). -
offset: Number indicating number of entries to skip before starting iteration (starts at 0 by default). -
versions: Boolean indicating if versions should be included in returned entries (not by default). -
snapshot: Boolean indicating if a database snapshot is used for iteration (true by default).
LMDB supports multiple databases per environment (an environment corresponds to a single memory-mapped file). When you initialize an LMDB database with open, the database uses the default root database. However, you can use multiple databases per environment/file and instantiate a database for each one. If you are going to be opening many databases, make sure you set the maxDbs (it defaults to 12). For example, we can open multiple databases for a single environment:
import { open } from 'lmdb';
let rootDB = open('all-my-data');
let usersDB = myDB.openDB('users');
let groupsDB = myDB.openDB('groups');
let productsDB = myDB.openDB('products');Each of the opened/returned databases has the same API as the default database for the environment. Each of the databases for one environment also share the same batch queue and automated transactions with each other, so immediately writing data from two databases with the same environment will be batched together in the same commit. For example:
usersDB.put('some-user', { data: userInfo });
groupsDB.put('some-group', { groupData: moreData });Both these puts will be batched and committed in the same transaction in the next event turn. Also, you can start a transaction from one database and make writes from any of the databases in that same environment (and they will be a part of the same transaction):
rootDB.transaction(() => {
usersDB.put('some-user', { data: userInfo });
groupsDB.put('some-group', { groupData: moreData });
});It is important to note that named databases will be added as entries to the root database. Consequently adding entries to the root database will be in the same key-value space as the metadata for named databases, and which can be confusing and mixing usage of entries in the root database with named databases is not recommended.
This returns the version number of the last entry that was retrieved with get (assuming it was a versioned database). If you are using a database with cache enabled, use getEntry instead.
This can be used to directly store a buffer or Uint8Array as a value, bypassing any encoding. If you are using a database with an encoding that isn't binary, setting a value with a Uint8Array will typically be encoded with the db's encoding (for example MessagePack wraps in a header, preserving its type for get). However, if you want to bypass encoding, for example, if you have already encoded a value, you can use asBinary:
let buffer = encode(myValue) // if we have already serialized a value, perhaps to compare it or check its size
db.put(key, asBinary(buffer)) // we can directly store the encoded valueThis allows you to explicitly start a read transaction, which holds a consistent snapshot of the database, and use it for subsequent retrieval operations. This will mark the read transaction as in use until transaction.done() is called. For example:
let transaction = myDb.useReadTransaction();
let data = myDb.get('my-key', { transaction });
await doSomethingElse();
// the same read transaction is still being used and this will return the same record even if the data has been changed elsewhere:
data = myDb.get('my-key', { transaction });
transaction.done(); // make sure you mark the transaction as doneIt is critical that you mark read transactions as done when you no longer need it or you will exhaust the read transactions that are available. Long-lived read transaction also prevent free space reclamation. This can be used with get, getEntry and range/query methods.
This will close the current db. This closes the underlying LMDB database, and if this is the root database (opened with open as opposed to db.openDB), it will close the environment (and child databases will no longer be able to interact with the database). This is asynchronous, waiting for any outstanding transactions to finish before closing the database.
This checks if an entry exists for the given key, and optionally verifies that the version or value exists. If this is a dupSort enabled database, you can provide the key and value to check if that key/value entry exists. If you are using a versioned database, you can provide a version number to verify if the entry for the provided key has the specific version number. This returns true if the entry does exist.
This will retrieve the binary data at the specified key. This is just like get, except it will always return the value's binary representation as a buffer, rather than decoding with the db's encoding format (if there is no entry, undefined will still be returned).
This will retrieve the binary data at the specified key, like getBinary, except it uses reusable buffers, which is faster, but means the data in the buffer is only valid until the next get operation (including cursor operations). Since this is a reusable buffer it also slightly differs from a typical buffer: the length property is set to the length of the value (what you typically want for normal usage), but the byteLength will be the size of the full allocated memory area for the buffer (usually much larger).
With larger databases and situations where the data in the database may not be cached in memory, it may be advisable to use asynchronous methods to fetch data to avoid slow/expensive hard-page faults on the main thread. This method provides a means of asynchronously fetching data in separate thread/asynchronously to ensure data is in memory. This fetches the data for given ids and accesses all pages to ensure that any hard page faults are done asynchronously. Once completed, synchronous gets to the same entries will most likely be in memory and fast. The prefetch can also be run in parallel with sync gets (for the same entries) in situations where the main thread be busy with deserialization and other work at roughly the same rate as the prefetch page faults might occur.
Asynchronously gets the values stored by the given ids and return the values in array corresponding to the array of ids. This uses prefetch followed by gets for each entry once the data is prefetched.
These methods remove all the entries from a database (asynchronously or synchronously, respectively).
These methods remove all the entries from a database and delete that database (asynchronously or synchronously, respectively).
Safely makes a snapshot backup copy of the database at the specified target path.
Normally, this library will automatically start a reader transaction for get and range operations, periodically reseting the read transaction on new event turns and after any write transactions are committed, to ensure it is using an up-to-date snapshot of the database. However, you can call resetReadTxn if you need to manually force the read transaction to reset to the latest snapshot/version of the database. In particular, this may be useful running with multiple processes where you need to immediately reset the read transaction based on a known update in another process (rather than waiting for the next event turn).
LMDB and this library are designed for high concurrency, and we recommend using multiple processes to achieve concurrency (processes are more robust than threads, and thread's advantage of shared memory is minimal with separate JavaScript workers, and you still get shared memory access with processes when using LMDB). Versioning or asynchronous transactions are the preferred method for achieving atomicity with data updates with concurrency. A version can be stored with an entry, and later the data can be updated, conditional on the version being the expected version. This provides a robust mechanism for concurrent data updates even with multiple processes are accessing the same database. To enable versioning, make sure to set the useVersions option when opening the database:
let myDB = open('my-db', { useVersions: true });You can set a version by using the version argument in put calls. You can later update data and ensure that the data will only be updated if the version matches the expected version by using the ifVersion argument. When retrieving entries, you can access the version number by calling getLastVersion().
You can then make conditional writes, examples:
myDB.put('key1', 'value1', 4, 3); // new version of 4, only if previous version was 3myDB.ifVersion('key1', 4, () => {
myDB.put('key1', 'value2', 5); // equivalent to myDB.put('key1', 'value2', 5, 4);
myDB.put('anotherKey', 'value', 3); // we can do other puts based on the same condition above
// we can make puts in other databases (from the same database environment) based on same condition too
myDB2.put('keyInOtherDb', 'value');
});
Asynchronous transactions are also a robust way to handle concurrency with multiple processes and provides a more traditional and flexible mechanism for making atomic ACID-compliant transactional data changes.
Shared structures are mechanism for storing the structural information about objects stored in database in dedicated entry, outside of individual entries, for reuse across all of the data in database, for much more efficient storage and faster retrieval of data when storing objects that have the same or similar structures (note that this is only available using the default MessagePack or CBOR encoding, using the msgpackr or cbor-x package). This is highly recommended when storing structured objects with similiar object structures (including inside of array). When enabled, when data is stored, any structural information (the set of property names) is automatically generated and stored in separate entry to be reused for storing and retrieving all data for the database. To enable this feature, simply specify the key where shared structures can be stored. You can use a symbol as a metadata key, as symbols are outside of the range of the standard JS primitive values:
let myDB = open('my-db', {
sharedStructuresKey: Symbol.for('structures')
})Once shared structures has been enabled, you can persist JavaScript objects just as you would normally would, and this library will automatically generate, increment, and save the structural information in the provided key to improve storage efficiency and performance. You never need to directly access this key, just be aware that that entry is being used by this library.
This library can optionally use off-thread LZ4 compression as part of the asynchronous writes to enable efficient compression with virtually no overhead to the main thread. LZ4 decompression (in get and getRange calls) is extremely fast and generally has a low impact on performance. Compression is turned off by default, but can be turned on by setting the compression property when opening a database. The value of compression can be true or an object with compression settings, including properties:
-
threshold- Only entries that are larger than this value (in bytes) will be compressed. This defaults to 1000 (if compression is enabled) -
dictionary- This can be buffer to use as a shared dictionary. This is defaults to a shared dictionary that helps with compressing JSON and English words in small entries. Zstandard provides utilities for creating your own optimized shared dictionary. For example:
let myDB = open('my-db', {
compression: {
threshold: 500, // compress any entry larger than 500 bytes
dictionary: fs.readFileSync('dict.txt') // use your own shared dictionary
}
})Compression is recommended for large databases that may be close to or larger than available RAM, to improve caching and reduce page faults. If you enable compression for a database, you must ensure that the data is always opened with the same compression setting, so that the data will be properly decompressed.
By default, opening a database from a root database will inherited the compression settings from the root database.
This library supports caching of entries from databases, and uses a LRU/LFU (LRFU) and weak-referencing caching mechanism for highly optimized caching and object tracking. There are several key potential benefits to using caching, including performance, key correlation with object identity, and immediate/synchronous access to saved data. Enabling caching will cache gets and puts, which can make frequent gets much faster. Caching is enabled by providing a truthy value for the cache property on the database options.
The weak-referencing mechanism works in harmony with JS garbage collection to allow objects to be cached without preventing GC, and retrieved from the cache until they have actually been collected from memory, making more efficient use of memory. This also can provide a guarantee of object identity correlation with keys: as long as retrieved object is in memory, a get will always return the existing object, and get never will return two copies of the same object (for the same key). The LRFU caching mechanism is scan-resistant, tracking frequency of usage as well as recency.
Because asynchronous put operations immediately go in the cache (and are pinned in the cache until committed), the caching enabled, put values can be retrieved via get, immediately and synchronously after the put call. Without caching enabled, you need wait for the put promise to resolve (or use asynchronous transactions) before you can access the stored value, but the cache enables the value to be immediately without waiting for the commit to finish:
db.put('hi', 'there');
db.get('hi'); // can immediately access value without having to await the promiseWhile caching can improve performance, LMDB itself is extremely fast, and for small objects with sporadic access, caching may not improve performance. Caching tends to provide the most performance benefits for larger objects that may have more significant deserialization costs. Caching does not apply to getRange queries. Also note that this requires Node 14.10 or higher (or Node v13.0 with --harmony-weak-ref flag).
If you are using caching with a database that has versions enabled, you should use the getEntry method to get the value and version, as getLastVersion will not be reliable (only returns the version when the data is accessed from the database).
Asynchronous single operations (put and remove) are executed in the order they were called, relative to each other. Likewise, asynchronous transaction callbacks (transaction and childTransaction) are also executed in order relative to other asynchronous transaction callbacks. However, by default all queued asynchronous transaction callbacks are executed after all queued asynchronous single operations. But, you can enable strict ordering so that asynchronous transactions executed in order with the asynchronous single operations, by setting the strictAsyncOrder property to true.
However, strict ordering comes with a couple of caveats. First, because asynchronous single operations are executed on separate transaction threads, but asynchronous transaction callbacks must execute on the main JS thread, if there is a lot of frequent switching back and forth between single operations and callbacks, this can significantly reduce performance since it requires substantial thread switching and event queuing.
Second, if there are asynchronous operations that have been performed, and asynchronous transaction callbacks that are waiting to be called, and a synchronous transaction is executed (transactionSync), this must interrupt and split the current asynchronous transaction batch, so the synchronous transaction can be executed (the synchronous transaction can not block to wait for the asynchronous if there are outstanding callbacks to execute as part of that async transaction, as that would result in a deadlock). This can potentially create an exception to the general rule that all asynchronous operations that are performed in one event turn will be part of the same transaction. Of course, each single asynchronous transaction callback is still guaranteed to execute in a single atomic transaction (and calls to transactionSync during a asynchronous transaction callback are simply executed as part of the current transaction). With the default ordering of 'after', it is possible for the async transactions to be performed in a separate transaction than the single operations if executed.
The open method can be used to create the main database/environment with the following signature:
open(path, options) or open(options)
Additional databases can be opened within the main database environment with:
db.openDB(name, options) or db.openDB(options)
If the path has an . in it, it is treated as a file name, otherwise it is treated as a directory name, where the data will be stored. The path can be omitted to create a temporary database, which will be created in the system temp directory and deleted on close. The options argument to either of the functions should be an object, and supports the following properties, all of which are optional (except name if not otherwise specified):
-
name- This is the name of the database. This defaults to null (which is the root database) when opening the database environment (open). When an opening a database within an environment (openDB), this is required, if not specified in first parameter. -
encoding- Sets the encoding for the database values, which can be'msgpack','json','cbor','string','ordered-binary'or'binary'. Child databases will inherit this from the root database, it is specified. -
encoder- Directly set the encoder to use or provide the settings for an encoder. This can be an object with settings to pass to the encoder or can be an object withencodeanddecodemethods. It can also be an object with anEncoderthat will be called to create the encoder instance. This allows you explicitly set the encoder with an import:
import * as cbor from 'cbor-x';
let db = open({ encoder: cbor });-
sharedStructuresKey- Enables shared structures and sets the key where the shared structures will be stored. -
compression- This enables compression. This can be set a truthy value to enable compression with default settings, or it can be an object with compression settings. -
cache- Setting this to true enables caching. This can also be set to an object specifying the settings/options for the cache (see settings for weak-lru-cache). For long-running synchronous operations, it is recommended that you set theclearKeptInterval(a value of 100 is a good choice). The object cache is stored separately for each process/worker, so if you are running across multiple workers or processes, you will either need to use messaging to invalidate cached entries when they are updated on other threads, or alternately, you can configure the cache to always check that the in-memory object matches the stored object with the flagvalidatedflag set totrue. For example, if you are using the cache with the multiple workers, the easiest way to ensure objects are always up-to-date is:
open({
cache: {
validated: true
}
})-
useVersions- Set this to true if you will be setting version numbers on the entries in the database. Note that you can not change this flag once a database has entries in it (or they won't be read correctly). -
keyEncoding- This indicates the encoding to use for the database keys, and can be'uint32'for unsigned 32-bit integers,'binary'for raw buffers/Uint8Arrays, and the default'ordered-binary'allows any JS primitive as a keys. -
keyEncoder- Provide a custom key encoder. -
dupSort- Enables duplicate entries for keys. Generally this is best used for building indices where the values represent keys to other databases, and it is recommended that you useencoding: 'ordered-binary'with this flag. You will usually want to retrieve the values for a key withgetValues. -
strictAsyncOrder- Maintain strict ordering of execution of asynchronous transaction callbacks relative to asynchronous single operations.
The following additional option properties are only available when creating the main database environment (open):
-
path- This is the file path to the database environment file you will use. -
maxDbs- The maximum number of databases to be able to open within one root database/environment (there is some extra overhead if this is set very high). This defaults to 12. -
maxReaders- The maximum number of concurrent read transactions (readers) to be able to open (more information). -
overlappingSync- This enables committing transactions where LMDB waits for a transaction to be fully flushed to disk after the transaction has been committed and defaults to being enabled on non-Windows OSes. This option is discussed in more detail below. -
separateFlushed- Resolve asynchronous operations when commits are finished and visible and include a separate promise for when a commit is flushed to disk, as aflushedproperty on the commit promise. Note that you can alternately use theflushedproperty on the database. -
pageSize- This defines the page size of the database. This defaults to the default page size of the OS (usually 4,096, except on MacOS with M-series, which is 16,384 bytes). You may want to consider setting this to 8,192 for databases larger than available memory (and moreso if you have range queries) or 4,096 for databases that can mostly cache in memory. Note that this only effects the page size of new databases (does not affect existing databases). -
eventTurnBatching- This is enabled by default and will ensure that all asynchronous write operations performed in the same event turn will be batched together into the same transaction. Disabling this allows lmdb-js to commit a transaction at any time, and asynchronous operations will only be guaranteed to be in the same transaction if explicitly batched together (withtransaction,batch,ifVersion). If this is disabled (set tofalse), you can control how many writes can occur before starting a transaction withtxnStartThreshold(allow a transaction will still be started at the next event turn if the threshold is not met). Disabling event turn batching (and using lowertxnStartThresholdvalues) can facilitate a faster response time to write operations.txnStartThresholddefaults to 5. -
encryptionKey- This enables encryption, and the provided value is the key that is used for encryption. This may be a buffer or string, but must be 32 bytes/characters long. This uses the Chacha8 cipher for fast and secure on-disk encryption of data. -
commitDelay- This is the amount of time to wait (in milliseconds) for batching write operations before committing the writes (in a transaction). This defaults to 0. A delay of 0 means more immediate commits with less latency (usessetImmediate), but a longer delay (which usessetTimeout) can be more efficient at collecting more writes into a single transaction and reducing I/O load. Note that NodeJS timers only have an effective resolution of about 10ms, so acommitDelayof 1ms will generally wait about 10ms.
In addition, the following options map to LMDB's env flags, described here. None of these need to be set, the defaults can always be used and are generally recommended, but these are available for various needs and performance optimizations:
-
noSync- Does not explicitly flush data to disk at all. This can be useful for temporary databases where durability/integrity is not necessary, and can significantly improve write performance that is I/O bound. However, we discourage this flag for data that needs integrity and durability in storage, since it can result in data loss/corruption if the computer crashes. -
noMemInit- This provides a small performance boost for writes, by skipping zero'ing out malloc'ed data, but can leave application data in unused portions of the database. If you do not need to worry about unauthorized access to the database files themselves, this is recommended. -
remapChunks- This a flag to specify if dynamic memory mapping should be used. Enabling this generally makes read operations a little bit slower, but frees up more mapped memory, making it friendlier to other applications. This is enabled by default on 32-bit operating systems (which require this to go beyond 4GB database size) ifmapSizeis not specified, otherwise it is disabled by default. -
mapSize- This can be used to specify the initial amount of how much virtual memory address space (in bytes) to allocate for mapping to the database files. Setting a map size will typically disableremapChunksby default unless the size is larger than appropriate for the OS. Different OSes have different allocation limits. -
useWritemap- Use writemaps, this can improve performance by reducing malloc calls and file writes, but can increase risk of a stray pointer corrupting data, and may be slower on Windows. Combined withnoSync, normal reads/writes/transactions involve virtually zero explicit I/O calls, only modifications to memory maps that the OS persists when convenient, which may be beneficial. -
noMetaSync- This isn't as dangerous asnoSync, but doesn't improve performance much either. -
noReadAhead- This disables read-ahead caching. Turning it off may help random read performance when the DB is larger than RAM and system RAM is full. However, this is not supported by all OSes, including Windows, and should not be used in conjunction with page sizes larger than 4,096. -
noSubdir- Treatpathas a filename instead of directory (this is the default if the path appears to end with an extension and has '.' in it) -
safeRestore- When usingoverlappingSync, lmdb-js will use the latest committed transaction if the OS's boot id hasn't changed, but this will force lmdb-store to always use the latest safely flushed transaction even if the boot id hasn't changed. -
readOnly- Self-descriptive. -
mapAsync- Not recommended, commits are already performed in a separate thread (asyncronous to JS), and this prevents accurate notification of when flushes finish.
The overlappingSync option enables transactions to be committed such that LMDB waits for a transaction to be fully flushed to disk after the transaction has been committed. This option is enabled by default on non-Windows operating systems. This means that the expensive/slow disk flushing operations do not occur during the writer lock, and allows disk flushing to occur in parallel with future transactions, providing potentially significant performance benefits. This uses a multi-step process of updating meta pointers to ensure database integrity even if a crash occurs.
When this is enabled, there are two events of potential interest: when the transaction is committed and the data is visible (to all other threads/processes), and when the transaction is flushed and durable. The write actions return a promise for when they are committed. The database includes a flushed property with a promise-like object that resolves when the last commit is fully flushed/synced to disk and is durable. Alternately, the separateFlushed option can be enabled and for write operations, the returned promise will still resolve when the transaction is committed and the promise will also have a flushed property that holds a second promise that is resolved when the OS reports that the transaction writes has been fully flushed to disk and are truly durable (at least as far the hardward/OS is capable of guaranteeing this). For example:
let db = open('my-db', { overlappingSync: true });
let written = db.put(key, value);
await written; // wait for it to be committed
let v = db.get(key) // this value now be retrieved from the db
await db.flushed // wait for last commit to be fully flushed to diskEnabling overlappingSync option is generally not recommended on Windows, as Window's disk flushing operation tends to have very poor performance characteristics on larger databases (whereas Windows tends to perform well with standard transactions). This option is enabled by default for non-Windows platforms.
If you are using the default encoding of 'msgpack', the msgpackr package is used for serialization and deserialization. You can provide encoder options that are passed to msgpackr or cbor, as well, by including them in the encoder property object. For example, these options can be potentially useful:
-
structuredClone- This enables the structured cloning extensions that will encode object/cyclic references and additional built-in types/classes. -
useFloat32: 4- Encode floating point numbers in 32-bit format when possible.
You can also use the CBOR format by specifying the encoding of 'cbor' and installing the cbor-x package, which supports the same options.
Custom key encoding can be useful for defining more efficient encodings of specific keys like UUIDs. Custom key encoding can be specified by providing a keyEncoder object with the following methods:
-
writeKey(key, targetBuffer, startPosition)- This should write the provided key to the target buffer and returning the end position in the buffer. -
readKey(sourceBuffer, start, end)- This should read the key from the provided buffer, with provided start and end position in the buffer, returning the key.
The database instance is an EventEmitter, allowing application to listen to database events. There is just one event right now:
beforecommit - This event is fired before a transaction finishes/commits. The callback function can perform additional (asynchronous) writes (put and remove) and they will be included in the transaction about to be performed as the last operation(s) before the transaction commits (this can be useful for updating a global version stamp based on all previous writes, for example). Using this event forces eventTurnBatching to be enabled. This can be called multiples times in a transaction, but should always be called as the last operation of a transaction.
If you have an existing application built on LevelUp, the lmdb-js is designed to make it easy to transition to this package, with most of the LevelUp API implemented and supported in lmdb-js. This includes the put, del, batch, status, isOperation, and getMany functions. One key difference in APIs is that LevelUp uses asynchronous callback based gets, but lmdb-js is so fast that it generally returns from get call before an an event can even be queued, consequently lmdb-js uses synchronous gets. However, there is a levelup export that can be used to generate a new database instance with LevelUp's style of API for get (although it still runs synchronously):
let dbLevel = levelup(db)
dbLevel.get(id, (error, value) => {
})
// or
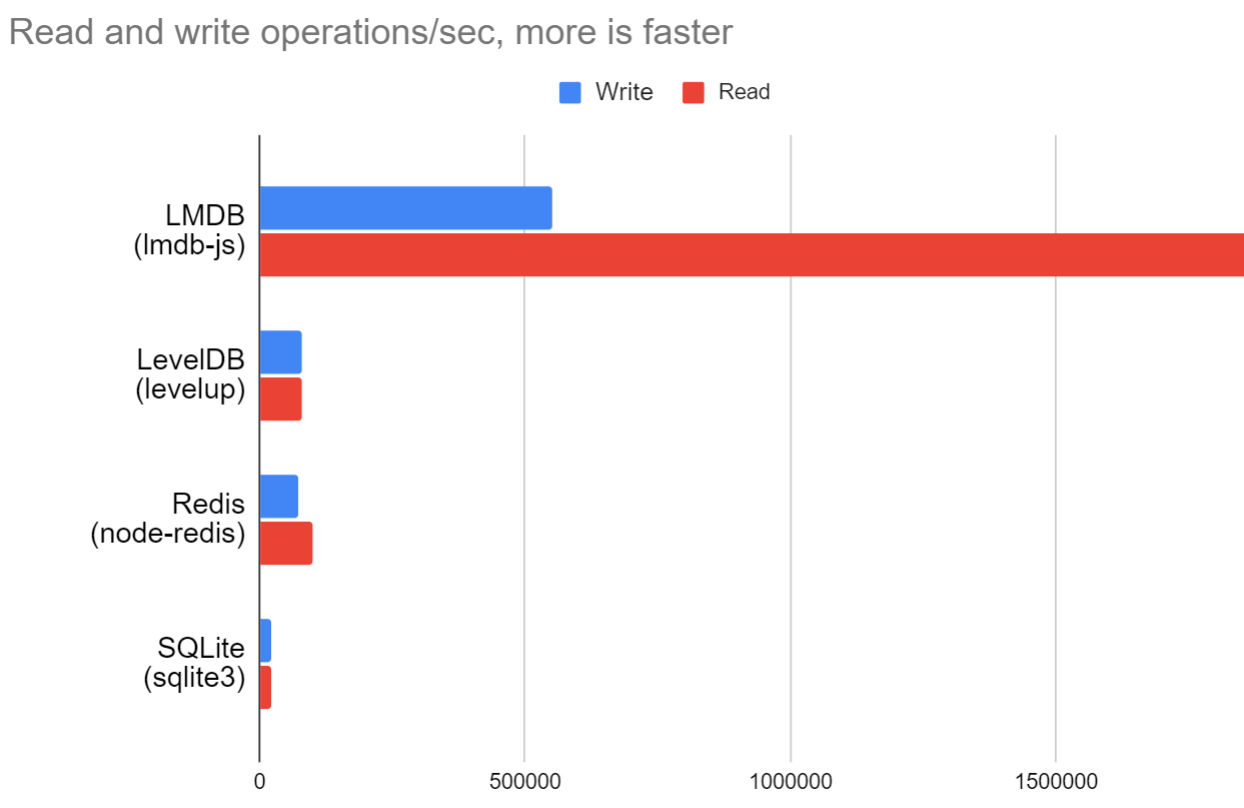
dbLevel.get(id).then(...)Benchmarking on Node 14.9, with 3.4Ghz i7-4770 Windows, a get operation, using JS numbers as a key, retrieving data from the database (random access), and decoding the data into a structured object with 10 properties (using default MessagePack encoding), can be done in about half a microsecond, or about 1,900,000/sec on a single thread. This is almost three times as fast as a single native JSON.parse call with the same object without any DB interaction! LMDB scales effortlessly across multiple processes or threads; over 6,000,000 operations/sec on the same 4/8 core computer by running across multiple threads (or 18,000,000 operations/sec with raw binary data). By running writes on a separate transactional thread, writing is extremely fast as well. With encoding the same objects, full encoding and writes can be performed at about 500,000 puts/second or 1,700,000 puts/second on multiple threads.
This package includes an NPM executable to download all the prebuilds for all OS/architectures. This can be useful if
you are building a full set of files/artifacts to be run on different machines. This requires installing the prebuildify-ci package (globally is recommended) and adding something like this to your package.json:
{
"dependencies": {
"lmdb": "2.6.0"
},
"scripts": {
"download-lmdb-prebuilds": "download-lmdb-prebuilds"
}
}
A few LMDB options are available at build time, and can be specified with options with npm install (which can be specified in your package.json install script):
npm install lmdb --build-from-source --use_robust=false: This will disable LMDB's MDB_USE_ROBUST option, which uses robust semaphores/mutexes so that if you are using multiple processes, and one process dies in the middle of transaction, the OS will cleanup the semaphore/mutex, aborting the transaction and allowing other processes to run without hanging. There is a slight performance overhead to robust mutexes, but keeping this enabled is recommended if you will be using multiple processes.
On MacOS, there is a default limit of 10 robust locked semaphores, which imposes a limit on the number of open write transactions (if you have over 10 database environments with a write transaction). If you need more concurrent write transactions, you can increase your maximum undoable semaphore count with:
sudo sysctl kern.sysv.semume=50
Otherwise you may need to disable the robust mutex option. You can also try to minimize overlapping transactions and/or reduce the number of database environments (and use more databases within each environment).
npm install lmdb --build-from-source --use_data_v1=true: This will build from an older version of LMDB that uses the legacy data format version 1 (the latest LMDB uses data format version 2). For portability of the data format, this may be preferable since many libraries still use older versions of LMDB. Since this is an older version of LMDB, some features may not be available, including encryption and remapping.
On Node V16+, lmdb-js will automatically enable V8's turbo fast-api calls (the --turbo-fast-api-calls V8 flag) to accelerate lmdb-js's turbo-enabled functions. If you do not want this flag enabled, set the env variable DISABLE_TURBO_CALLS=true for your node process, or build from source with --enable_fast_api_calls=false.
The lmdb-js project is developed in conjunction with lmdbx-js, which is based on libmdbx, a fork of LMDB. Each of these have their own advantages:
- lmdb-js/LMDB is great for general usage, has very high performance, easy to set up with automated sizing, supports encryption, and works well across all platforms.
- lmdbx-js/libmdbx has more advanced management of free space and database sizing that can offer more performance optimizations for situations that require intense free space reclamation. However, in my experience lmdb-js has better performance than lmdbx-js, and the database format is not compatible with LMDB.
This library is built on LMDB and is built from and derived from the excellent node-lmdb package.
Many thanks to Rod Vagg for donating the lmdb package name in the NPM registry.
This library is licensed under the terms of the MIT license.
Also note that LMDB: Symas (the authors of LMDB) offers commercial support of LMDB.
This project has no funding needs. If you feel inclined to donate, donate to one of Kris's favorite charities like Innovations in Poverty Action or any of GiveWell's recommended charities.