![]()
Hyntax
Straightforward HTML parser for JavaScript. Live Demo.
- Simple. API is straightforward, output is clear.
- Forgiving. Just like a browser, normally parses invalid HTML.
- Supports streaming. Can process HTML while it's still being loaded.
- No dependencies.
Table Of Contents
Usage
npm install hyntaxconst tokenize constructTree = const util = const inputHTML = `<html> <body> <input type="text" placeholder="Don't type"> <button>Don't press</button> </body></html>` const tokens = const ast = consoleconsoleTypeScript Typings
Hyntax is written in JavaScript but has integrated TypeScript typings to help you navigate around its data structures. There is also Types Reference which covers most common types.
Streaming
Use StreamTokenizer and StreamTreeConstructor classes to parse HTML chunk by chunk while it's still being loaded from the network or read from the disk.
const StreamTokenizer StreamTreeConstructor = const http = const util = httpTokens
Here are all kinds of tokens which Hyntax will extract out of HTML string.
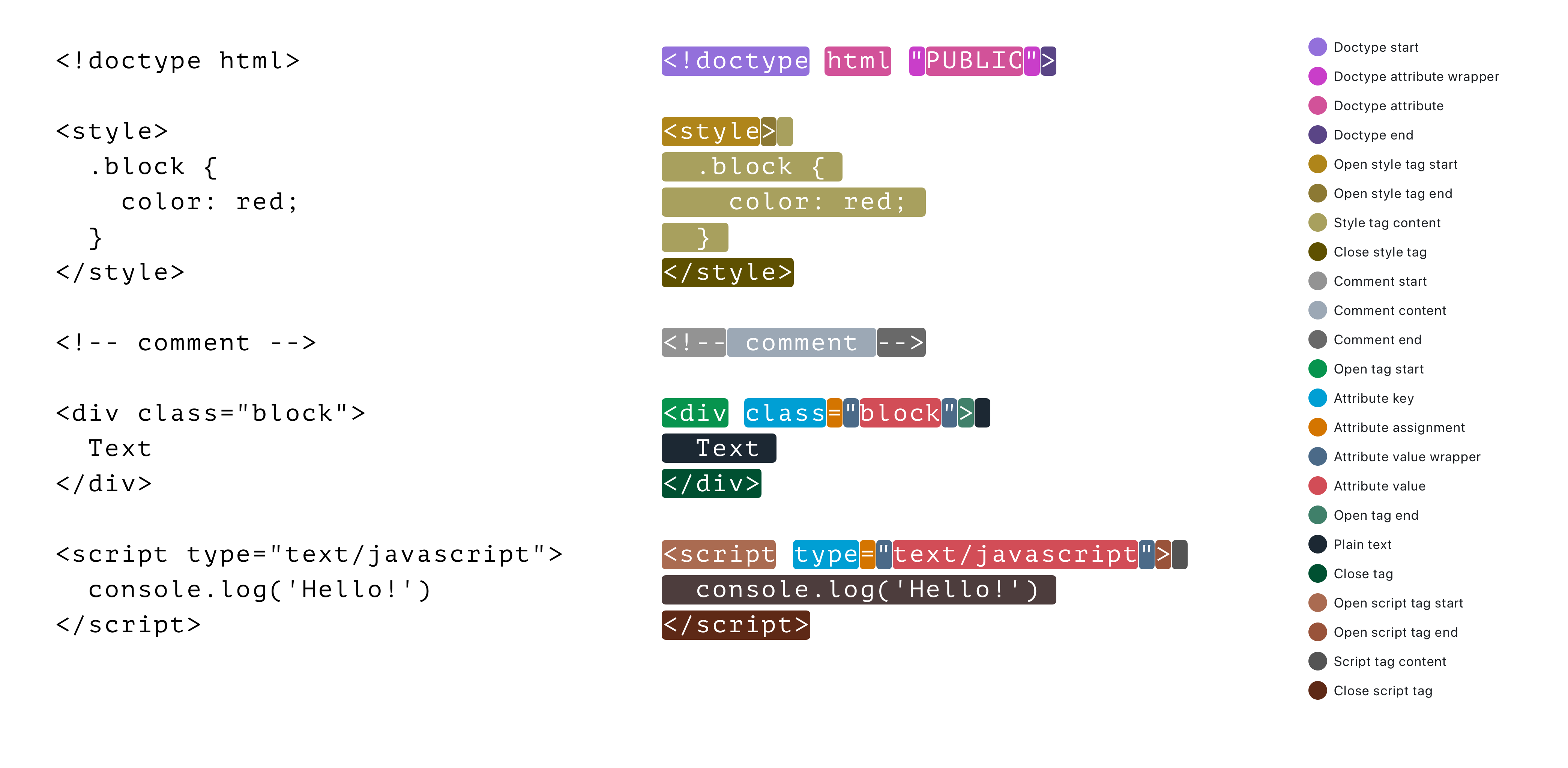
Each token conforms to Tokenizer.Token interface.
AST Format
Resulting syntax tree will have at least one top-level Document Node with optional children nodes nested within.
nodeType: TreeConstructorNodeTypesDocument content: children: nodeType: TreeConstructorNodeTypesAnyNodeType content: … nodeType: TreeConstructorNodeTypesAnyNodeType content: … Content of each node is specific to node's type, all of them are described in AST Node Types reference.
API Reference
Tokenizer
Hyntax has its tokenizer as a separate module. You can use generated tokens on their own or pass them further to a tree constructor to build an AST.
Interface
tokenizehtml: String: Tokenizer.ResultArguments
html
HTML string to process
Required.
Type: string.
Returns Tokenizer.Result
Tree Constructor
After you've got an array of tokens, you can pass them into tree constructor to build an AST.
Interface
constructTreetokens: Tokenizer.AnyToken: TreeConstructor.ResultArguments
tokens
Array of tokens received from the tokenizer.
Required.
Type: Tokenizer.AnyToken[]
Returns TreeConstructor.Result
Types Reference
Tokenizer.Result
state
The current state of tokenizer. It can be persisted and passed to the next tokenizer call if the input is coming in chunks.tokens
Array of resulting tokens.
Type: Tokenizer.AnyToken[]
TreeConstructor.Result
-
state
The current state of the tree constructor. Can be persisted and passed to the next tree constructor call in case when tokens are coming in chunks. -
ast
Resulting AST.
Type: TreeConstructor.AST
Tokenizer.Token
Generic Token, other interfaces use it to create a specific Token type.
-
type
One of the Token types. -
content
Piece of original HTML string which was recognized as a token. -
startPosition
Index of a character in the input HTML string where the token starts. -
endPosition
Index of a character in the input HTML string where the token ends.
Tokenizer.TokenTypes.AnyTokenType
Shortcut type of all possible tokens.
Tokenizer.AnyToken
Shortcut to reference any possible token.
TreeConstructor.AST
Just an alias to DocumentNode. AST always has one top-level DocumentNode. See AST Node Types
AST Node Types
There are 7 possible types of Node. Each type has a specific content.
Interfaces for each content type:
TreeConstructor.Node
Generic Node, other interfaces use it to create specific Nodes by providing type of Node and type of the content inside the Node.
TreeConstructor.NodeTypes.AnyNodeType
Shortcut type of all possible Node types.
Node Content Types
TreeConstructor.NodeTypes.AnyNodeContent
Shortcut type of all possible types of content inside a Node.
TreeConstructor.NodeContents.Document
TreeConstructor.NodeContents.Doctype
TreeConstructor.NodeContents.Text
TreeConstructor.NodeContents.Tag
TreeConstructor.NodeContents.Comment
TreeConstructor.NodeContents.Script
TreeConstructor.NodeContents.Style
TreeConstructor.DoctypeAttribute
TreeConstructor.TagAttribute