Unishox Javascript Library - Guaranteed Compression for Short Strings
![]()

This library was developed to individually compress and decompress small strings. In general compression utilities such as zip, gzip do not compress short strings well and often expand them. They also use lots of memory which makes them unusable in constrained environments like Arduino.
Note: The present byte-code version is 2 and it replaces Unishox 1. Unishox 1 is still available here only as a C Library.
Applications
- Compression for low memory devices such as Arduino, ESP8266 and ESP32
- Sending messages over Websockets
- Compression of Chat application text exchange including Emojis
- Storing compressed text in database
- Bandwidth and storage cost reduction for Cloud technologies

How it works
Unishox is an hybrid encoder (entropy, dictionary and delta coding). It works by assigning fixed prefix-free codes for each letter in the above Character Set (entropy coding). It also encodes repeating letter sets separately (dictionary coding). For Unicode characters, delta coding is used.
The model used for arriving at the prefix-free code is shown below:
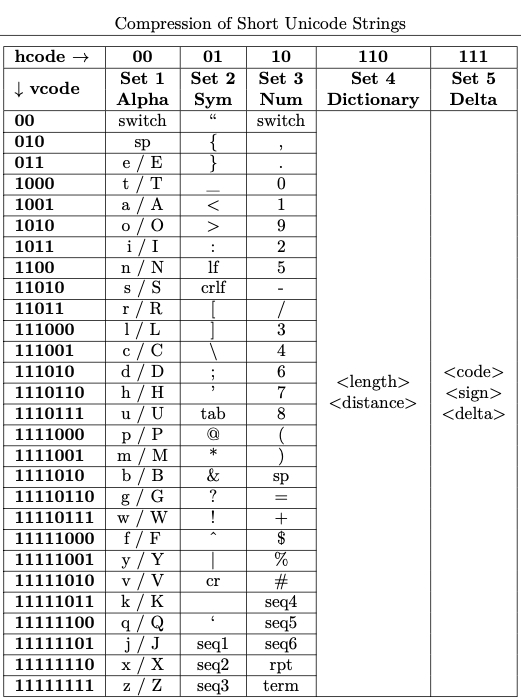
The complete specification can be found in this article: Unishox 2 - Guaranteed Configurable Compression for Short Strings using Entropy, Dictionary and Delta encoding techniques.
Getting started
This is a Node.js library, but is made to work even with older Javascript versions to make it compatible with low memory IoT devices.
There are no dependencies. Unishox2.js is all you will need to integrate with your application.
This library is available at npm at https://www.npmjs.com/package/unishox2.siara.cc and can be included in your Javascript projects with npm i unishox2.siara.cc. See below on how to include it in your code.
Running Unit tests (using Jest)
To run unit tests, clone this repo and issue following commands, assuming npm is installed:
npm update
npm run testTrying it out with your own strings
You can check out what kind of compression you get with what strings using demo_unishox2.js:
node demo_unishox2.js "The quick brown fox jumped over the lazy dog"and the output would be:

Using it in your application
To compress and decompress strings in your application, import unishox2.js:
var usx = require("./unishox2.js");The function expects a Javascript string or Uint8Array as Input and Output an Uint8Array.
Simple API
In its simplest form, just pass the string you want to compress, its length and a UintArray to receive the compressed contents. While the library can make the output array, it is faster to supply it. Since this technology guarantees compression, the output buffer needs be only as lengthy as the input string 99.99% of times:
var usx = require("./unishox2.js")
var my_str = "The quick brown fox jumped over the lazy dog";
var out_buf = new Uint8Array(100); // A buffer with arbitrary length
var out_len = usx.unishox2_compress_simple(my_str, my_str.length, out_buf);
var out_str = usx.unishox2_decompress_simple(out_buf, out_len);
console.log(out_str);As shown above, the original string can be obtained by passing the UintArray and length to unishox2_decompress_simple.
More advanced API for customizing according to your context
Depending on the input string, you can press more juice out of the compressor by hinting the type of text being compressed. Following are the parameters that can be tuned:
- Composition of text, numbers, symbols, repetitions, unicode characters
- Frequently occurring sequences
- Templates such as for Date/Time, GUID and Phone numbers
16 presets are provided with the demo program based on the type of text you may intend to compress:
- Default, that is optimized for all types of texts
- Alphabets and space only
- Alphanumeric and space only
- Alphanumeric, symbols and space only
- Alphanumeric, symbols and space only, favouring English sentences
- Support all types, but favour Alphanumeric
- Support all types, but favour repeating sequences
- Support all types, but favour symbols
- Support all types, but favour Umlaut characters
- Favor all types except repeating sequences
- Favor all types except Unicode characters
- Favor all types, especially English text, except Unicode characters
- Favor URLs
- Favor JSON
- Favor JSON, but no Unicode Characters
- Favor XML
- Favor HTML
Please refer to unishox_compress_lines and unishox_decompress_lines functions in the library to make use of these. However in most cases, the default Simple API provides optimimum compression.
Please see here for API documentation.
Interoperability with the C Library
Strings that were compressed with this library can be decompressed with the C Library and vice-versa. It always works if the input is composed of ASCII characters between 32 to 126. For other UTF-8 inputs, if you wish the output to be used with the other library, please always provide the input as a Uint8Array and output as Uint8Array and not as a Javascript string as shown below:
var usx = require("./unishox2.js")
var utf8bytes = new TextEncoder().encode("La beauté est pas dans le visage. La beauté est la lumière dans le coeur.");
var cbuf = new Uint8Array(100); // A buffer with arbitrary length
var clen = usx.unishox2_compress_simple(utf8bytes, utf8bytes.length, cbuf);
var out_str = usx.unishox2_decompress_simple(out_buf, out_len);
console.log(out_str); // This won't work
var dbuf = new Uint8Array(100); // A buffer with arbitrary length
var dlen = usx.unishox2_decompress(cbuf, clen, dbuf, usx.USX_HCODES_DFLT, usx.USX_HCODE_LENS_DFLT, usx.USX_FREQ_SEQ_DFLT, usx.USX_TEMPLATES);
out_str = new TextDecoder("utf-8").decode(dbuf);
console.log(out_str); // This works and cbuf and clen can be passed to the C Library for decompressionThe reason for having to use UTF-8 encoded byte buffers is that the distances for repeating sequences are stored in number of bytes and it varies between a Javascript string and the corresponding UTF-8 encoded set of bytes.
The Jest Unit test program downloads the C library, compiles it and compares the compressed output of each string in the test suite with that of the C library.
Integrating with Firebase Firestore
Unishox can be used to store more data than the 1GB free limit in Firestore database by storing text content as a Blob. For example,
var usx = require("./unishox2.js")
var my_str = "The quick brown fox jumped over the lazy dog";
var out_buf = new Uint8Array(100); // A buffer with arbitrary length
var out_len = usx.unishox2_compress_simple(my_str, my_str.length, out_buf);
firebase.firestore().collection("/my-collection").add({
myCompressedBlob: firebase.firestore.Blob.fromUint8Array(out_buf.slice(0, out_len))
});Since the size of compressed content will be smaller than the input text, more than 1GB data can be compressed and stored into Firestore. The compression ratio will depend on the type of text that is being compressed.
Character Set
Unishox supports the entire Unicode character set. As of now it supports UTF-8 as input and output encoding.
Projects that use Unishox
- Unishox C Library
- Unishox Compression Library for Arduino Progmem
- Sqlite3 User Defined Function as loadable extension
- Sqlite3 Library for ESP32
- Sqlite3 Library for ESP8266
- Port of Unishox 1 to Python and C++ by Stephan Hadinger for Tasmota
- Python bindings for Unishox2
Credits
- Thanks to Jonathan Greenblatt for his port of Unishox2 that works on Particle Photon
- Thanks to Chris Partridge for his port of Unishox2 to CPython and his comprehensive tests using Hypothesis and extensive performance tests.
- Thanks to Stephan Hadinger for his port of Unishox1 to Python for Tasmota
Issues
In case of any issues, please email the Author (Arundale Ramanathan) at arun@siara.cc or create GitHub issue.