uCourse-crawler
🎒 Scrape the courses info from the University of Nottingham's website. (Different campuses and academic years supported.)
Requirements
- Nodejs
- MongoDB (optional)
Usage
git clone https://github.com/Songkeys/uCourse-crawler.gitcd uCourse-crawlernpm inpm startDemo
Output Methods
There are two output methods provided:
- MongoDB (Recommended)
- Local JSON file
Output (MongoDB)
For mongoDB, you will need to input a mongo connection string URI. The output will be stored in a table called course_[campus]_[year]. E.g. course_china_2020.
The output example:

Output (JSON file)
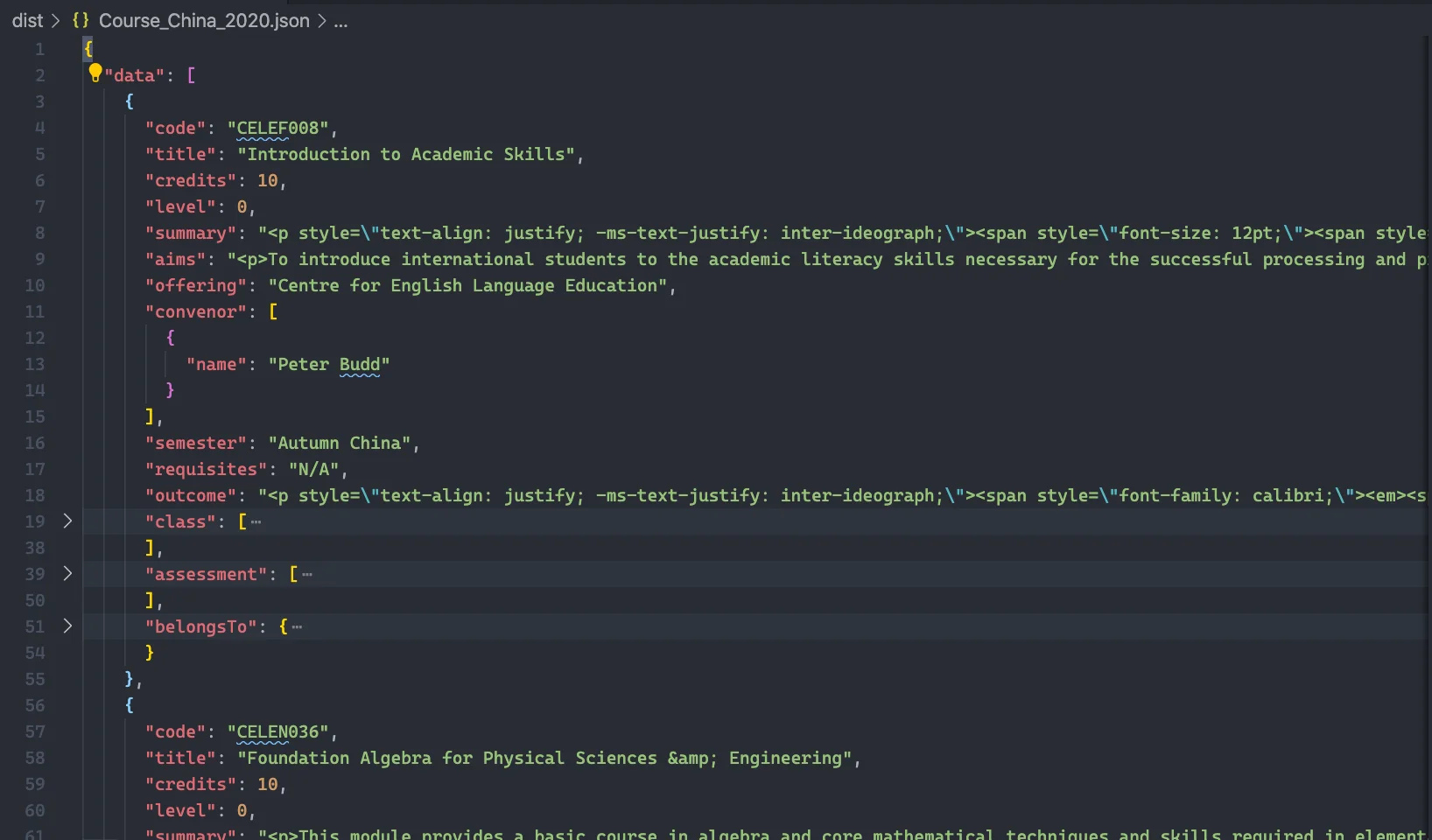
For local JSON file, the output will be in a JSON format stored in /dist/[tablename].json.
The output example:
Size & Time
The estimated output size will be 2~3 MB per campus per year.
The estimated crawling time will be 30~50 mins per campus per year (depending on your network).
Todo
- Concurency using pupeteer-cluster
- Breakpoint resume
Resources
- Resouce website: https://mynottingham.nottingham.ac.uk/psp/psprd/EMPLOYEE/HRMS/c/UN_PROG_AND_MOD_EXTRACT.UN_PAM_CRSE_EXTRCT.GBL
- There is also a short url for this: https://u.nu/course. (You may need to visit twice to open it for some authorization issue.)