mongo-table-admin (MTA)
Admin interface for mongo. Work with documents as table rows. Integrates Handsontable - great inline edit tool, and Pivottable - data discovery and analisys tool.
![]()


why
For me, data collection is usually not just a valid json. You can say I'm an old style, but I'd like to understand data structure, trends, clusters etc. Thats what pivot is about. And second thing, I like to fix data easyly when I see small problems. Not like a SQL query, but inlide edit - just like Excel table.
If you are looking for a full featured mongo admin, please check:
Rememeber to always back up important data. Everybody can sometimes unintentionally break something.
demo
try demo on heroku (give it a moment to wake up)
Don't have local mongodb or one with secure url access? Get 500MB free on mLabs
features
- Inline edit using Handsontable. Add new rows. Delete rows. Add or modify columns.
- Browse, analyze documents using Pivottable - group by rows, columns. Build graphs, export small datasets.
- Query documents using JSON or new Visual Query Editor. Count before loading data. Manage projection and limit.
- Use goodies like run sync function on every document, find dupes or group count.
- Create new collection copy-pasting data from any source. Set data type - Number, Boolean, Array, Object, Date. String is by default.
- Import data from xls, xlsx, csv, json, and those zipped.
- Manage indexes, browse or edit collection schema.
installation
git clone https://github.com/artbels/mongo-table-admin.git && cd mongo-table-admin
npm start
localhost:12369
security
ip control by setting list of IPs in MTA_IPS environment variable
export MTA_IPS=
usage
add rows (localhost:12369/create) example on youtube:
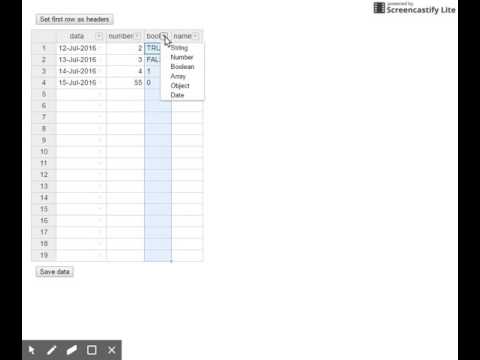
browse data (localhost:12369) example on youtube:
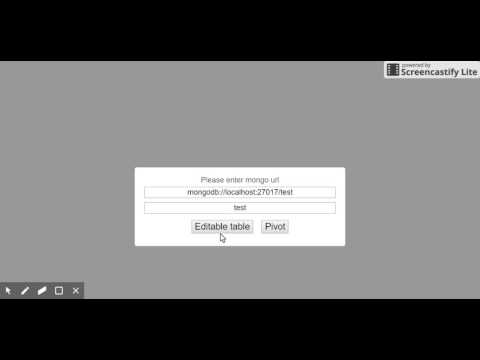
inline edit data (localhost:12369) example on youtube:
plans
- [*] multiple times faster saving and deleting using concurrent requests and grouping
- [*] use Visual QueryBuilder to build queries
- [*] use ace editor for json edit
- [*] set projection and limit for query
- [*] add/delete multiple fields at once
- [*] refactor schema management
- select whether to run function for the whole collection or based on query
- refactor "create" view
limitations
- connection string should match "mongodb://:@:/"
- documents must have an "_id" property which should be a string, integer or MongoDB ObjectId
contribution & help
- be free to fork github.com/artbels/mongo-table-admin. Ex. add custom auth.
- found something broken? Take a minute to post an issue or request pull.