JavaScriptで一からsqliteクローンを書いて、シンプルなデータベースを構築しよう。
このレポジトリは Let's Build a Simple Database を元に日本語訳し、さらにJavaScriptで実装したものになります
データベースはどのように動いているのでしょうか
- データは(メモリとディスク上で)どのような形式で保存されるのでしょう
- メモリからディスクへの移動はどのタイミングでしょう
- テーブルごとに主キーを1つだけもつのはなぜですか
- トランザクションのロールバックはどのように行われるのですか
- インデックスはどのようにフォーマットされるのですか
- テーブルのフルスキャンはいつ、どのように行われるのですか
- Prepared Statementはどのような形式で保存されるのでしょうか
- 要するに、データベースはどのように動いているのでしょうか
それを理解するためにJavaScriptでスクラッチからsqliteのクローンを作り、その過程を文章化していきたいと思います。
目次は下記です
- パート1 - はじめに - REPLの紹介とセットアップ
- パート2 - 世界で最もシンプルなSQLコンパイラと仮想マシン
- パート3 - インメモリ、Append-Only、シングルテーブルデータベース
- パート4 - 初めてのテスト(とバグ
- パート5 - ディスクへの永続性
- パート6 - カーソルの抽象化
- パート7 - B-Treeの紹介
- パート8 - B-Tree リーフノードのフォーマット
- パート9 - バイナリ検索と重複キー
- パート10 - リーフノードの分割
- パート11 - B-Treeを再帰的に検索する
- パート12 - マルチレベルBツリーのスキャン
- パート13 - 分割後の親ノードの更新
"私が自分で作れないものは、私が本当の意味で理解していないものだ。" - リチャード・ファインマン
パート1 - はじめに - REPLの紹介とセットアップ
Web開発者として、仕事では毎日のようにリレーショナルデータベースを使っていますが、 これはブラックボックスのような存在です。 あなたは下記のような疑問を抱くでしょう
- データは(メモリとディスク上で)どのような形式で保存されるのでしょう
- メモリからディスクへの移動はどのタイミングでしょう
- テーブルごとに主キーを1つだけもつのはなぜですか
- トランザクションのロールバックはどのように行われるのですか
- インデックスはどのようにフォーマットされるのですか
- テーブルのフルスキャンはいつ、どのように行われるのですか
- Prepared Statementはどのような形式で保存されるのでしょうか
- 要するに、データベースはどのように動いているのでしょうか
これらを理解するために、私はゼロからデータベースを書いています。 これはsqliteをモデルにしていますが、 MySQLやPostgreSQLよりも機能が少なく、小さく設計されているので、理解しやすくなっています。 なんとデータベース全体が一つのファイルに格納されているのです!
Sqlite
sqliteのウェブサイトにはsqlite内部のドキュメントがたくさんありますし、 SQLite Database Systemのコピーもあります。 ここでは「Design and Implementation」を引用させていただきました。
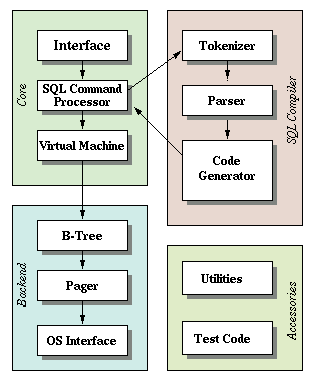
クエリは、データを取得したり変更したりするために、コンポーネントのチェーンを通過します。フロントエンドは
- トークナイザー
- パーサ
- コード生成器
フロントエンドへの入力はSQLクエリで、出力はsqlite仮想マシンのバイトコード(基本的にはデータベース上で動作するコンパイル済みのプログラム)です。 から構成されています。
- 仮想マシン
- B-Tree
- Pager
- OSインターフェース
仮想マシンはフロントエンドで生成されたバイトコードを命令として受け取ります。 そして、1つまたは複数のテーブルまたはインデックスに対して操作を実行することができ、それぞれがB-Treeと呼ばれるデータ構造に格納されています。 仮想マシンは、基本的にはバイトコード命令の種類に関するビッグスイッチ文です。
各B-Treeは多数のノードで構成されています。各ノードは1ページの長さです。 B-tree は、Pagerにコマンドを発行することで、ディスクからページを取得したり、ディスクに保存したりすることができます。
Pagerは、データのページを読み書きするコマンドを受け取ります。それは、データベースファイル内の適切なオフセットでの読み書きを担当します。 また、最近アクセスしたページのキャッシュをメモリに保持し、それらのページがいつディスクに書き戻される必要があるかを判断します。
OSインタフェースは、sqliteがどのオペレーティングシステム用にコンパイルされたかによって異なるレイヤです。 このチュートリアルでは、複数のプラットフォームをサポートするつもりはありません。
千里の道も一歩からというkと、もう少し簡単なものから始めてみましょう。
簡単なREPLの作成
Sqliteはコマンドラインから起動すると、読み込み-実行-表示ループを起動します。
~ sqlite3SQLite version 3.16.0 2016-11-04 19:09:39Enter ".help" for usage hints.Connected to a transient in-memory database.Use ".open FILENAME" to reopen on a persistent database.sqlite> create table users (id int, username varchar(255), email varchar(255));sqlite> .tablesuserssqlite> .exit~これを行うために、メイン関数はプロンプトを表示し、入力行を取得し、その入力行を処理する無限ループを持つことになります。
getline()と対話するために保存する必要がある状態の小さなラッパーとしてInputBufferを定義します。(これについての詳細は後ほど)
次に、print_prompt() はユーザにプロンプトを表示します。入力の各行を読み込む前にこれを行います。
入力された行を読み込むには、getline()を使用します。
lineptr : 読み込んだ行を含むバッファを指すために使用する変数へのポインタ。これがNULLに設定されている場合、getlineによってmallocattedされているため、コマンドが失敗した場合でもユーザが解放しなければなりません。 n : 変数へのポインタで、割り当てられたバッファのサイズを保存します。 stream : 読み出す入力ストリーム。ここでは標準入力から読み込みます。 戻り値 : 読み込んだバイト数。 読み込んだ行をinput_buffer->bufferに、割り当てられたバッファのサイズをinput_buffer->buffer_lengthに格納するようにgetlineに指示します。戻り値は input_buffer->input_length に格納します。 bufferはnullで始まるので、getlineは入力行を保持するのに十分なメモリを確保し、bufferを指すようにしています。
あとはInputBuffer *のインスタンスに割り当てられたメモリと、それぞれの構造体のbuffer要素を解放する関数を定義するのが適切です(getlineはread_inputでinput_buffer->bufferのメモリを確保します)。
最後に、コマンドを解析して実行します。現在認識できるコマンドは一つしかありません: .exit はプログラムを終了させます。それ以外の場合は、エラーメッセージを表示してループを続けます。
試しにやってみましょう!
~ ./dbdb > .tablesUnrecognized command '.tables'.db > .exit~さて、これでREPLが完成しました。次のパートでは、コマンド言語の開発を始めます。その間に、このパートのプログラム全体を紹介します。