
EntropyString for JavaScript
![]()


Efficiently generate cryptographically strong random strings of specified entropy from various character sets.
TOC
- Installation
- Usage
- Overview
- Real Need
- More Examples
- Character Sets
- Custom Characters
- Efficiency
- Custom Bytes
- No Crypto
- Browser Version
- Entropy Bits
- Why You Don't Need UUIDs
- Upgrading
- Take Away
Installation
Yarn
yarn add entropy-stringNPM
npm install entropy-stringUsage
Generate strings as an efficient replacement to using version 4 UUIDs
const entropy = const string = entropyGtTr2h4PT2mjffm2GrDN2rhpqp
See the UUID section for a discussion of why the above is more efficient than using the string representation of version 4 UUIDs.
Generate a potential of 1 million random strings with 1 in a billion chance of repeat
const Entropy = const entropy = total: 1e6 risk: 1e9 const string = entropypbbnBD4MQ3rbRN
See Real Need for description of what the total and risk parameters represent.
Hexidecimal strings
EntropyString uses predefined charset32 characters by default (see Character Sets). To get a random hexadecimal string:
const Entropy charset16 = const entropy = total: 1e6 risk: 1e9 charset: charset16 const string = entropy878114ac513a538e22
Custom characters
Custom characters may also be specified. Using uppercase hexadecimal characters:
const Entropy = const entropy = total: 1e6 risk: 1e9 charset: '0123456789ABCDEF' const string = entropy16E26779479356B516
Convenience functions
Convenience functions smallID, mediumID, largeID, sessionID and token provide random strings for various predefined bits of entropy. For example, a small id represents a potential of 30 strings with a 1 in a million chance of repeat:
const Entropy = const entropy = const string = entropyDpTQqg
Or, to generate an OWASP session ID:
const Entropy = const entropy = const string = entropynqqBt2P669nmjPQRqh4NtmTPn9
Or perhaps you need an 256-bit token using RFC 4648 file system and URL safe characters:
const Entropy charset64 = const entropy = charset: charset64 const string = entropyt-Z8b9FLvpc-roln2BZnGYLZAX_pn5U7uO_cbfldsIt
Examples
Run any of the examples in the examples directory by:
yarn examplesnode examples/dist/tldr_1.jsOverview
EntropyString provides easy creation of randomly generated strings of specific entropy using various character sets. Such strings are needed as unique identifiers when generating, for example, random IDs and you don't want the overkill of a UUID.
A key concern when generating such strings is that they be unique. Guaranteed uniqueness, however, requires either deterministic generation (e.g., a counter) that is not random, or that each newly created random string be compared against all existing strings. When randomness is required, the overhead of storing and comparing strings is often too onerous and a different tack is chosen.
A common strategy is to replace the guarantee of uniqueness with a weaker but often sufficient one of probabilistic uniqueness. Specifically, rather than being absolutely sure of uniqueness, we settle for a statement such as "there is less than a 1 in a billion chance that two of my strings are the same". We use an implicit version of this very strategy every time we use a hash set, where the keys are formed from taking the hash of some value. We assume there will be no hash collision using our values, but we do not have any true guarantee of uniqueness per se.
Fortunately, a probabilistic uniqueness strategy requires much less overhead than guaranteed uniqueness. But it does require we have some manner of qualifying what we mean by "there is less than a 1 in a billion chance that 1 million strings of this form will have a repeat".
Understanding probabilistic uniqueness of random strings requires an understanding of entropy and of estimating the probability of a collision (i.e., the probability that two strings in a set of randomly generated strings might be the same). The blog post Hash Collision Probabilities provides an excellent overview of deriving an expression for calculating the probability of a collision in some number of hashes using a perfect hash with an N-bit output. This is sufficient for understanding the probability of collision given a hash with a fixed output of N-bits, but does not provide an answer to qualifying what we mean by "there is less than a 1 in a billion chance that 1 million strings of this form will have a repeat". The Entropy Bits section below describes how EntropyString provides this qualifying measure.
We'll begin investigating EntropyString by considering the Real Need when generating random strings.
Real Need
Let's start by reflecting on the common statement: I need random strings 16 characters long.
Okay. There are libraries available that address that exact need. But first, there are some questions that arise from the need as stated, such as:
- What characters do you want to use?
- How many of these strings do you need?
- Why do you need these strings?
The available libraries often let you specify the characters to use. So we can assume for now that question 1 is answered with:
Hexadecimal will do fine.
As for question 2, the developer might respond:
I need 10,000 of these things.
Ah, now we're getting somewhere. The answer to question 3 might lead to a further qualification:
I need to generate 10,000 random, unique IDs.
And the cat's out of the bag. We're getting at the real need, and it's not the same as the original statement. The developer needs uniqueness across a total of some number of strings. The length of the string is a by-product of the uniqueness, not the goal, and should not be the primary specification for the random string.
As noted in the Overview, guaranteeing uniqueness is difficult, so we'll replace that declaration with one of probabilistic uniqueness by asking a fourth question:
- What risk of a repeat are you willing to accept?
Probabilistic uniqueness contains risk. That's the price we pay for giving up on the stronger declaration of guaranteed uniqueness. But the developer can quantify an appropriate risk for a particular scenario with a statement like:
I guess I can live with a 1 in a million chance of a repeat.
So now we've finally gotten to the developer's real need:
I need 10,000 random hexadecimal IDs with less than 1 in a million chance of any repeats.
Not only is this statement more specific, there is no mention of string length. The developer needs probabilistic uniqueness, and strings are to be used to capture randomness for this purpose. As such, the length of the string is simply a by-product of the encoding used to represent the required uniqueness as a string.
How do you address this need using a library designed to generate strings of specified length? Well, you don't, because that library was designed to answer the originally stated need, not the real need we've uncovered. We need a library that deals with probabilistic uniqueness of a total number of some strings. And that's exactly what EntropyString does.
Let's use EntropyString to help this developer generate 5 hexadecimal IDs from a pool of a potential 10,000 IDs with a 1 in a million chance of a repeat:
const Entropy charset16 = const entropy = total: 10000 risk: 1000000 charset: charset16 const strings = Array5["85e442fa0e83", "a74dc126af1e", "368cd13b1f6e", "81bf94e1278d", "fe7dec099ac9"]
Examining the above code, the total and risk parameters specify how much entropy is needed to satisfy the probabilistic uniqueness of generating a potential total of 10,000 strings with a 1 in a million risk of repeat. The charset parameter specifies the characters to use. Finally, the strings themselves are generated using entropy.string().
Looking at the IDs, we can see each is 12 characters long. It seems the developer didn't really need 16 characters after all. Again, the string length is a by-product of the characters used to represent the randomness (i.e. entropy) we needed. The strings would be shorter if we used either a 32 or 64 character set.
More Examples
In Real Need our developer used hexadecimal characters for the strings. Let's look at using other characters instead.
We'll start with using 32 characters. What 32 characters, you ask? The Character Sets section discusses the predefined characters available in EntropyString and the Custom Characters section describes how you can use whatever characters you want. By default, EntropyString uses charset32 characters, so we don't need to pass that parameter into new Entropy().
const Entropy = const entropy = total: 10000 risk: 1e6 const string = entropyString: MD8r3BpTH3
We're using the same total and risk as before, but this time we use 32 characters and our resulting ID are 10 characters.
As another example, let's assume we need to ensure the names of about 30 items are unique. And suppose we decide we can live with a 1 in 100,000 probability of collision (we're just futzing with some coding ideas). Using the predefined provided hex characters:
const Entropy charset16 charset4 = const entropy = total: 30 risk: 100000 charset: charset16 const string = entropyString: dbf40a6
Using the same Entropy instance, we can switch to the predefined charset4 characters and generate a string with those characters and the same amount of entropy:
entropystring = entropyString: CAATAGTGGACTG
Okay, we probably wouldn't use 4 characters (and what's up with those characters?), but you get the idea.
Suppose we have a more extreme need. We want less than a 1 in a trillion chance that 10 billion base 32 strings repeat. Let's see, our total of 10 billion is 1010 and our risk of 1 in a trillion is 1012, so:
const Entropy = const entropy = total: 1e10 risk: 1e12 const string = entropyString: 4J86pbFG9BqdBjTLfD3rt6
Finally, let say we're generating session IDs. Since session IDs are ephemeral, we aren't interested in uniqueness per se, but in ensuring our IDs aren't predictable since we can't have the bad guys guessing a valid session ID. In this case, we're using entropy as a measure of unpredictability of the IDs. Rather than calculate our entropy, we declare it as 128 bits (since we read on the OWASP web site that session IDs should be 128 bits).
const Entropy = const entropy = bits: 128 const string = entropyString: Rm9gDFn6Q9DJ9rbrtrttBjR97r
Since session ID are such an important need, EntropyString provides a convenience function for generating them:
const Entropy charset64 = const entropy = charset: charset64 const string = entropyString: DUNB7JHqXCibGVI5HzXVp2
Character Sets
As we've seen in the previous sections, EntropyString provides predefined character sets. Let's see what's under the hood.
const charset64 = const chars = charset64ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_
The available CharSets are charset64, charset32, charset16, charset8, charset4 and charset2. The predefined characters for each were chosen as follows:
charset64: ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_- The file system and URL safe char set from RFC 4648.
charset32: 2346789bdfghjmnpqrtBDFGHJLMNPQRT- Remove all upper and lower case vowels (including y)
- Remove all numbers that look like letters
- Remove all letters that look like numbers
- Remove all letters that have poor distinction between upper and lower case values.
charset16: 0123456789abcdef- Hexadecimal
charset8: 01234567- Octal
charset4: ATCG- DNA alphabet. No good reason; just wanted to get away from the obvious.
charset2: 01- Binary
The default CharSet is charset32. The random strings using the characters of that set result in strings don't look like English words and yet are easy to parse visually.
You may, of course, want to choose the characters used, which is covered next in Custom Characters.
Custom Characters
Being able to easily generate random strings is great, but what if you want to specify your own characters. For example, suppose you want to visualize flipping a coin to produce entropy of 10 bits.
const Entropy charset2 = const entropy = charset: charset2 bits: 10 let flips = entropyflips: 1111001011
The resulting string of 0's and 1's doesn't look quite right. Perhaps you want to use the characters H and T instead.
entropyflips = entropyflips: THHTHTTHHT
As another example, we saw in Character Sets the predefined hex characters for charset16 are lowercase. Suppose you like uppercase hexadecimal letters instead.
const Entropy = const entropy = charset: '0123456789ABCDEF' bits: 48 const string = entropystring: 08BB82C0056A
The Entropy constructor allows for the following cases:
- No argument:
charset32characters and 128bits
- { total: T, risk: R }:
charset32characters and sufficientbitsto ensure a potential of T strings with a risk of repeat being 1 in R
- { bits: N }:
charset32characters and Nbits
- { charset:
CharSet}:- One of six predefined
CharSets can be specified
- One of six predefined
- { charset: chars }:
- A string representing the characters to use can be specified
- A combination of
charsetand eitherbitsortotal,risk
If a string of characters is used, an EntropyStringError will be thrown if the characters aren't appropriate for creating a valid CharSet.
const Entropy = try const entropy = charset: '123456' catcherror consoleInvalid character count: must be one of 2,4,8,16,32,64
try const entropy = charset: '01233210' catcherror consoleCharacters not unique
Efficiency
To efficiently create random strings, EntropyString generates the necessary number of bytes needed for each string and uses those bytes in a bit shifting scheme to index into a character set. For example, consider generating strings from the charset32 character set. There are 32 characters in the set, so an index into an array of those characters would be in the range [0,31]. Generating a random string of charset32 characters is thus reduced to generating a random sequence of indices in the range [0,31].
To generate the indices, EntropyString slices just enough bits from the array of bytes to create each index. In the example at hand, 5 bits are needed to create an index in the range [0,31]. EntropyString processes the byte array 5 bits at a time to create the indices. The first index comes from the first 5 bits of the first byte, the second index comes from the last 3 bits of the first byte combined with the first 2 bits of the second byte, and so on as the byte array is systematically sliced to form indices into the character set. And since bit shifting and addition of byte values is really efficient, this scheme is quite fast.
The EntropyString scheme is also efficient with regard to the amount of randomness used. Consider the following common JavaScript solution to generating random strings. To generate a character, an index into the available characters is create using Math.random. The code looks something like:
const chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"let string = ""forlet i = 0; i < length; i++ string += chars;bl0mvxXAqXuz5R3N
There are two significant issues with this code. Math.random returns a random float value. At the very best this value has about 53-bits of entropy. Let's assume it's 52-bits for argument sake, i.e. Math.random generates 52 bits of randomness per call. That randomness is in turn used to create an index into the 62 chars, each which represents 5.95 bits of entropy. So if we're creating strings with length=16, the 16 calls generate a total of 16*52 = 816 bits of randomness which are used to inject a total of 95.2 bits of entropy (5.95/char) into string. That means 720 bits (88% of the total) of the generated randomness is simply wasted.
Compare that to the EntropyString scheme. For the example above, slicing off 5 bits at a time requires a total of 80 bits (10 bytes). Creating the same strings as above, EntropyString uses 80 bits of randomness per string with no wasted bits. In general, the EntropyString scheme can waste up to 7 bits per string, but that's the worst case scenario and that's per string, not per character!
const Entropy = const entropy = bits: 80 let string = entropyHFtgHQ9q9fH6B8HM
But there is an even bigger issue with the previous code from a security perspective. Math.random is not a cryptographically strong random number generator. Do not use Math.random to create strings used for security purposes! This highlights an important point. Strings are only capable of carrying information (entropy); it's the random bytes that actually provide the entropy itself. EntropyString automatically generates the necessary bytes needed to create cryptographically strong random strings using the crypto library.
However, if you don't need cryptographically strong random strings, you can request EntropyString use the psuedo-random number generator (PRNG) Math.random rather than the crypto library by using passing the param prng: true to the Entropy constructor:
const Entropy = const entropy = bits: 80 prng: true string = entropyfdRp9Q3rTMF7TdFN
When using Math.random, the EntropyString scheme uses 48 of the 52(ish) bits of randomness from each call to Math.random. That's much more efficient than the previous code snippet but a bit less so than using bytes from crypto. And of course, being a PRNG, Math.random yields a deterministic sequence.
Fortunately you don't need to really understand how the bytes are efficiently sliced and diced to get the string. But you may want to provide your own Custom Bytes to create a string, which is the next topic.
Custom Bytes
As described in Efficiency, EntropyString automatically generates random bytes using the crypto library. But you may have a need to provide your own bytes, say for deterministic testing or to use a specialized byte generator. The entropy.string function allows passing in your own bytes to create a string.
Suppose we want a string capable of 30 bits of entropy using 32 characters. We pass in 4 bytes to cover the 30 bits needed to generate six base 32 characters:
const Entropy = const entropy = const bytes = Bufferlet string = entropyTh7fjL
The bytes provided can come from any source. However, the number of bytes must be sufficient to generate the string as described in the Efficiency section. entropy.stringWithBytes throws an Error if the string cannot be formed from the passed bytes.
try string = entropycatcherror consoleerror: Insufficient bytes: need 5 and got 4
Note the number of bytes needed is dependent on the number of characters in our set. In using a string to represent entropy, we can only have multiples of the bits of entropy per character used. So in the example above, to get at least 32 bits of entropy using a character set of 32 characters (5 bits per char), we'll need enough bytes to cover 35 bits, not 32, so an Error is thrown.
No Crypto
By default, EntropyString uses the crypto library for the cryptographically strong random bits used to systematically index into the chosen character set. If cryptographically strong strings are not required, EntropyString can use the psuedo-random number generator Math.random by passing prng: true to the Entropy constructor:
const Entropy = const entropy = total: 1e5 risk: 1e7 prng: true const string = entropyMJNhBg842J6
Browser Version
A browser version of EntropyString is packaged as a UMD bundle in the file entropy-string.browser.js with an export name of EntropyString . Rather than use the crypto library, the browser version uses window.crypto.getRandomValues for generating random bits. See examples/browser.html for example usage.
Entropy Bits
Thus far we've avoided the mathematics behind the calculation of the entropy bits required to specify a risk that some number random strings will not have a repeat. As noted in the Overview, the posting Hash Collision Probabilities derives an expression, based on the well-known Birthday Problem, for calculating the probability of a collision in some number of hashes (denoted by k) using a perfect hash with an output of M bits:
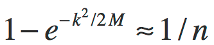
There are two slight tweaks to this equation as compared to the one in the referenced posting. M is used for the total number of possible hashes and an equation is formed by explicitly specifying that the expression in the posting is approximately equal to 1/n.
More importantly, the above equation isn't in a form conducive to our entropy string needs. The equation was derived for a set number of possible hashes and yields a probability, which is fine for hash collisions but isn't quite right for calculating the bits of entropy needed for our random strings.
The first thing we'll change is to use M = 2^N, where N is the number of entropy bits. This simply states that the number of possible strings is equal to the number of possible values using N bits:
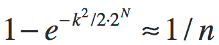
Now we massage the equation to represent N as a function of k and n:
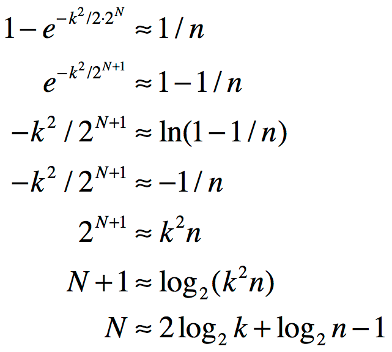
The final line represents the number of entropy bits N as a function of the number of potential strings k and the risk of repeat of 1 in n, exactly what we want. Furthermore, the equation is in a form that avoids really large numbers in calculating N since we immediately take a logarithm of each large value k and n.
Why You Don't Need UUIDs
It is quite common in most (all?) programming languages to simply use string representations of UUIDs as random strings. While this isn't necessarily wrong, it is not efficient. It's somewhat akin to using a BigInt library to do math with small integers. The answers might be right, but the process seems wrong.
By UUID, we almost always mean the version 4 string representation, which looks like this:
hhhhhhhh-hhhh-4hhh-Hhhh-hhhhhhhhhhhh
Per Section 4.4 of RFC 4122, the algorithm for creating 32-byte version 4 UUIDs is:
- Set bits 49-52 to the 4-bit version number, 0100
- The 13th hex char will always be 4
- Set bit 65-66 to 10.
- The 17th hex char will be one of 8, 9, A or B
- Set all the other bits to randomly (or pseudo-randomly) chosen values
The algorithm designates how to create the 32 byte UUID. The string representation shown above is specified in Section 3 of the RFC.
The ramifications of the algorithm and string representation are:
- The specification does not require the use of a cryptographically strong pseudo-random number generator. That's fine, but if using the IDs for security purposes, be sure a CSPRNG is being used to generate the random bytes for the UUID.
- Because certain bits are fixed values, the entropy of the UUID is reduced from 128 bits to 122 bits. This may not be a significant issue in some cases, but regardless of how often you read otherwise, a version 4 UUID does not have 128 bits of randomness. And if you use version 4 UUIDs for session IDs, that does not cover the OWASP recommendation of using 128-bit IDs.
- The string representation with hyphens adds overhead without adding any bits of entropy.
As a quick aside, let me emphasize that a string does not inherently possess any given amount of entropy. For example, how many bits of entropy does the version 4 UUID string 7416179b-62f4-4ea1-9201-6aa4ef920c12 have? Given the structure of version 4 UUIDs, we know it represents at most 122 bits of entropy. But without knowing how the bits were actually generated, we can't know how much entropy has actually been captured. Consider that statement carefully if you ever look at one of the many libraries that claim to calculate the entropy of a given string. The underlying assumption of how the string characters are generated is crucial (and often glossed over). Buyer beware.
Now, back to why you don't need to use version 4 UUIDs. The string representation is fixed, and uses 36 characters. Suppose we define as a metric of efficiency the number of bits in the string representation as opposed to the number of entropy bits. Then for a version 4 UUID we have:
- UUID
- Entropy bits: 122
- String length: 36
- String bits: 288
- Efficiency: 42%
Let's create a 122 entropy bit string using charset64:
const Entropy charset64 = const entropy = bits: 122 charset: charset64 const string = entropy- Entropy String:
- Entropy bits: 126
- String length: 21
- String bits: 168
- Efficiency: 75%
Using charset64 characters, we create a string representation with 75% efficiency vs. the 42% achieved in using version 4 UUIDs. Given that generating random strings using EntropyString is as easy as using a UUID library, I'll take 75% efficiency over 42% any day.
(Note the actually bits of entropy in the string is 126. Each character in charset64 carries 6 bits of entropy, and so in this case we can only have a total entropy of a multiple of 6. The EntropyString library ensures the number of entropy bits will meet or exceed the designated bits.)
But that's not the primary reason for using EntropyString over UUIDs. With version 4 UUIDs, the bits of entropy is fixed at 122, and you should ask yourself, "why do I need 122 bits"? And how often do you unquestioningly use one-size fits all solutions anyway?
What you should actually ask is, "how many strings do I need and what level of risk of a repeat am I willing to accept"? Rather than one-size fits all solutions, you should seek understanding and explicit control. Rather than swallowing 122-bits without thinking, investigate your real need and act accordingly. If you need IDs for a database table that could have 1 million entries, explicitly declare how much risk of repeat you're willing to accept. 1 in a million? Then you need 59 bits. 1 in a billion? 69 bits. 1 in a trillion? 79 bits. But openly declare and quit using UUIDs just because you didn't think about it! Now you know better, so do better :)
And finally, don't say you use version 4 UUIDs because you don't ever want a repeat. The term 'unique' in the name is misleading. Perhaps we should call them PUID for probabilistically unique identifiers. (I left out "universal" since that designation never really made sense anyway.) Regardless, there is a chance of repeat. It just depends on how many UUIDs you produce in a given "collision" context. Granted, it may be small, but it is not zero! It's just a probability that you didn't explicitly specify and may not even have really understood.
Upgrading
Version 3
EntropyString version 3 does not introduce any new functionality. The sole purpose of the version 3 release is to simplify and tighten the API. Backward incompatible changes made in this effort necessitated a semantic major release.
The two major changes are:
- Replace class
EntropyString.Randomwith classEntropyString.Entropy - Replace all camelCase
charSetNNwithcharsetNN
Change: EntropyString.Random -> EntropyString.Entropy
Change all instances of new Random() to new Entropy()
For example,
const Random = const random = const string = randombecomes
const Entropy = const random = const string = randomor
const Entropy = const entropy = const string = entropyChange: charSetNN -> charsetNN
Change all occurrences of charSetNN to charsetNN. charset is common enough in programming circles to negate the need for camelCase.
For example,
const Random charSet64 = const random = charSet64 const string = randombecomes
const Entropy charset64 = const entropy = charset64 const string = entropyOther minor changes:
- Remove
bitsWithRiskPowerandbitsWithPowersfromEntropy - Move predefined
CharSetdeclarations fromCharSettoEntropy Entropy.bitsis a class method of the newEntropyclass
Version 3.1
Version 3.1 introduced a new Entropy constructor API which tracks the specified entropy bits at the Entropy class level. This allows generating strings without passing the bits into the Entropy.string function. As example, consider the previous version 3.0 code:
const Entropy = const bits = Entropyconst entropy = const string = entropyUsing the new version 3.1 API, that code becomes:
const Entropy = const entropy = total: 1e6 risk: 1e12 const string = entropyVersion 4
Version 4 changes:
Entropyconstructor argument must be valid params- Embed
CharSetor character string in params object using{ charset: XYZ }
- Embed
- Default
Entropyconstructor params object is{ bits: 128, charset: charset32 }- Default behavior is the same as version 3.x
- Remove method
stringPRNGand deprecated methodstringRandomEntropyconstructor param{ prng: true }forces theEntropy.string()method to useMath.randomgenerated bytes
- Change signature of method
stringWithBytes(bitLen, bytes, <charset>)tostringWithBytes(bytes, <bitLen>, <charset>)(i.e.,bitLendefaults to theEntropyclass setting)- This change is parallel to the version 3.1 change to
Entropy.string()but required a semantic major version upgrade to implement
- This change is parallel to the version 3.1 change to
Take Away
- Don't specify randomness using string length
- String length is a by-product, not a goal
- Don't require truly uniqueness
- You'll do fine with probabilistically uniqueness
- Probabilistic uniqueness involves risk
- Risk is specified as "1 in n chance of generating a repeat"
- Explicity specify your intent
- Specified entropy as the risk of repeat in a total number of strings
- Characters used are arbitrary
- You need
EntropyString, not UUIDs
10 million strings with a 1 in a trillion chance of a repeat:
const Entropy = const entropy = total: 1e7 risk: 1e12 const string = entropyFrHbt3n9tBNTFMP6n